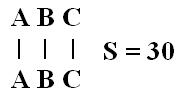
Constatare l'omologia fra due sequenze quando queste sono molto simili fra di loro è banale, in quanto sequenze molto simili ottengono punteggi molto alti. Quello che vogliamo ricercare sono omologie più remote, cioè quando il punteggio di similarità che otteniamo in output è dello stesso ordine di grandezza di quello che può ritrovarsi casualmente tra due sequenze.
Proponiamo un esempio che illustra il concetto appena espresso:
Assumiamo come sequenza query la sequenza ABC ed effettuiamo la ricerca per sequenze simili nel database contenente la sola sequenza ABC. Per ogni corrispondenza attribuiamo un punteggio pari a dieci altrimenti un punteggio pari a zero. Ovviamente si giunge a questo allineamento, con relativo punteggio :
Adesso assumiamo come sequenza query la sequenza ACB ottenuta scambiando gli ultimi due caratteri della prima sequenza, questa sequenza creata in modo artificioso ottiene un punteggio dello stesso ordine di grandezza del punteggio relativo alla sequenza query originale :
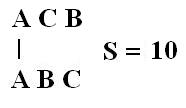
Mentre nel primo caso la correlazione biologica fra le due sequenze è certa ( le due sequenze sono uguali ), nel secondo caso, anche se in presenza di un punteggio elevato, non vi è alcuna correlazione biologica fra le due sequenze ( la sequenza query è artificialmente creata ). Ci occorre dunque sapere quali punteggi sono statisticamente significativi.
Per valutare la significatività statistica dell'output è necessario effettuare i seguenti passaggi :
Il punteggio della sequenza query originale ( Squery ) è confrontato con la distribuzione casuale per ricavare lo Z-score.
Lo Z-score è il numero di deviazioni standard che dividono Squery da Mcasuale :
Z-score = ( Squery - Mcasuale) / σ casuale
Un valore maggiore di 4 per lo Z-score indica che il punteggio Squery è al di fuori della distibuzione casuale attesa per la sequenza query, e che le sequenze che lo hanno generato sono omologhe.
BLAST inoltre calcola l'E-Value ( expectation value ), valore che indica il numero atteso di sequenze che hanno per caso punteggio Squery . Ovviamente questo valore quanto più prossimo allo zero sarà tanto più attesterà una correlazione biologica fra le sequenze.
L'E-Value è uguale ad K m n e^(-λS) dove K e λ sono costanti che dipendono dalla banca dati su cui si è effettuata la ricerca e dalla matrice di sostituzione usata nel calcolo del punteggio di similarità, m è la lunghezza della sequenza query, n è la lunghezza totale delle sequenze presenti nella banca dati e S è lo score dell'allineamento fra le due sequenze.