1- Introduzione
Il
Buffer Overflow è stata la più comune forma di vulnerabilità nella sicurezza per gli ultimi dieci
anni. Essa domina l'area relativa alla penetrazione in reti remote, dove, un
anonimo utente di Internet, cerca di ottenere un controllo parziale o totale di
un host. Se la vulnerabilità del buffer overflow potesse essere effettivamente
eliminata, una gran parte dei più seri trattati di sicurezza andrebbe eliminata
con essa.
1.1 - Buffer Overflow
Gli attacchi di tipo buffer overflow formano una sostanziale porzione di tutti gli attacchi alla sicurezza semplicemente perché le vulnerabilità del buffer overflow sono comuni e quindi facili da sfruttare. In ogni modo, le vulnerabilità del buffer overflow dominano la classe degli attacchi di intrusione perché esse offrono all'attaccante la possibilità di iniettare ed eseguire codice dannoso. Il codice d'attacco, iniettato, gira con i privilegi del programma vulnerabile e permette all'attaccante di poter invadere qualche altra funzionalità che gli interessa per controllare il computer host.
Per
esempio sui cinque attacchi remoto verso locale usati nel 1998[1] il
controllo sull'intrusione dei laboratori Lincoln ha evidenziato che tre erano
essenzialmente attacchi che ficcavano il naso nelle credenziali degli utenti,
mentre gli altri due erano buffer overflow.
1.2 - Gestione del
Buffer
1.2.1
- Alcune definizioni
Un buffer è
un blocco contiguo di memoria che contiene più istanze dello stesso tipo di
dato. In C un buffer viene chiamato array. Gli array in C possono essere dichiarati
statici o dinamici: le variabili statiche sono allocate al momento del caricamento
sul segmento dati, quelle dinamiche sono allocate al momento del caricamento
sullo stack. L'overflow consiste nel riempire un buffer oltre il limite.
I buffer di interesse sono quelli dinamici.
1.2.2
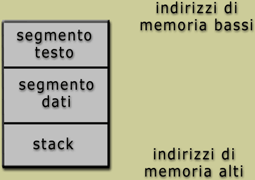
- Organizzazione della memoria di un processo
Per capire
come funzionano i buffer sullo stack occorre sapere com'è organizzata la
memoria di un processo. I processi sono divisi in tre regioni: testo, dati e
stack. La regione testo è fissata, contiene il codice del programma ed è
a sola lettura. Qualsiasi tentativo di scrittura provoca una violazione di
segmento. La regione dati contiene i dati inizializzati e non
inizializzati. Le variabili statiche vengono memorizzate in questa regione. La
dimensione di questa area può essere cambiata con la chiamata di sistema brk().
|
1.2.3 - Cos'è uno stack
Lo stack è
un tipo di dato astratto. Uno stack di oggetti ha la proprietà Last In First
Out (LIFO), cioè l'ultimo oggetto inserito è il primo ad essere rimosso. Le
due operazioni principali sono push e pop: push aggiunge
un elemento in cima allo stack e pop lo rimuove.
I linguaggi
di programmazione moderni hanno il costrutto di procedura o funzione. Una
chiamata a procedura altera il flusso di controllo come un salto (jump),
ma, diversamente da un salto, una volta finito il proprio compito, una funzione
ritorna il controllo all'istruzione successiva alla chiamata. Quest'astrazione
può essere implementata con il supporto di uno stack.
Lo stack è
usato anche per allocare dinamicamente le variabili locali usate nelle
funzioni, per passare parametri alle funzioni e per restituire valori dalle
stesse.
Uno stack è
un blocco di memoria contiguo contenente dei dati. Un registro noto come stack
pointer (SP) punta alla cima dello stack. La base dello stack è un
indirizzo fisso. La dimensione è variata dinamicamente dal kernel. La
CPU implementa le operazioni push e pop.
Lo stack
consiste di un insieme di segmenti logici (stack frame) che vengono
impilati sullo stack quando viene chiamata una funzione e spilati quando la
funzione ritorna. Uno stack frame contiene i parametri della funzione,
le sue variabili locali, i dati necessari per ripristinare il precedente stack
frame, incluso l'indirizzo dell'istruzione successiva alla chiamata
(contenuto nell'instruction pointer o IP).
A seconda
dell'implementazione, lo stack, cresce verso l'alto o il basso. In questa
trattazione si assume che cresca verso il basso, che è quanto succede sui
processori Intel, Motorola, SPARC e MIPS. Anche lo stack
pointer dipende dall'implementazione: può puntare all'ultimo indirizzo
sullo stack o al prossimo indirizzo libero. In questa discussione si assume che
punti all'ultimo indirizzo sullo stack.
Oltre allo stack
pointer si ha anche un frame pointer (FP) che punta ad una locazione
fissa nel frame, noto anche come base pointer (BP). Le variabili locali
possono essere referenziate specificando l'offset dallo stack pointer.
Tuttavia, poiché nuovi dati sono impilati e spilati, tale offset cambia. Quindi
si usa referenziare le variabili locali e i parametri con un offset da FP.
La prima cosa che fa una procedura quando viene chiamata, è salvare il FP precedente (per poterlo ripristinare al ritorno). Poi copia SP su FP per creare il nuovo FP ed incrementa SP per puntare allo spazio riservato per la successiva variabile locale. Questo codice è il prologo della procedura. Al momento dell'uscita dalla procedura, lo stack deve essere ripulito. Le funzioni delle CPU Intel per fare ciò sono ENTER e LEAVE, quelle delle CPU Motorola sono LINK e UNLINK. La trattazione successiva riguarda un sistema Linux su architettura Intel.
1.2.3.1
- Un esempio: La regione dello stack
Si consideri
un esempio e si analizzi lo stack:
void function(int a, int b,
int c) {
char buffer1[5];
char buffer2[10];
}
void main() {
function(1,2,3);
}
Per comprendere cosa faccia il programma per chiamare function(), lo si
compila per generare un output in codice assembly:
gcc -S -o example1 example1.c
Il codice assembly della chiamata di function() è:
pushl $3
pushl $2
pushl $1
call function
L'istruzione
call impila l'instruction pointer sullo stack. Questo IP salvato viene
chiamato indirizzo di ritorno o RET. Si consideri il prologo della funzione:
pushl %ebp
movl %esp,%ebp
subl $20,%esp
Questo
codice impila il base pointer EBP sullo stack, copia lo SP attuale su
EBP, rendendolo il nuovo FP. Il FP salvato viene detto saved frame pointer
o SFP. Poi alloca dello spazio per le variabili locali sottraendo la loro
dimensione a SP.
La memoria
può essere indirizzata solo a indirizzi multipli della dimensione di una
parola. Nel caso in questione una parola è di 4 byte. Quindi il buffer
dichiarato di 5 byte in realtà occupa 8 byte di memoria e quello di 10 byte ne
occupa 12. Perciò SP viene diminuito di 20. Lo stack è così fatto quando viene
chiamata function():
|

|
|
||
|
|
|
|
|
|
|
|