La parola steganografia deriva dall'unione dei due vocaboli greci stego (rendo occulto, nascondo) e grajh (la scrittura). Steganografia è dunque "la scrittura nascosta" o meglio ancora l'insieme delle tecniche che consente a due o più persone di comunicare in modo tale da nascondere non tanto il contenuto (come nel caso della crittografia), ma la stessa esistenza della comunicazione agli occhi di un eventuale osservatore, tradizionalmente denominato "nemico". Si tratta di un'idea tutt'altro che nuova e che anzi vanta origini molto antiche. Nel corso dei secoli sono stati escogitati numerosi metodi steganografici, tutti molto diversi tra loro. Al fine di comprendere meglio l'essenza di questa idea, può essere utile accennare ad alcuni esempi tra i più interessanti e ingegnosi.
Erodoto racconta la storia di un nobile persiano che fece tagliare a zero i capelli di uno schiavo fidato al fine di poter tatuare un messaggio sul suo cranio; una volta che i capelli furono ricresciuti, inviò lo schiavo alla sua destinazione, con la sola istruzione di tagliarseli nuovamente.
Un acrostico è una poesia - o un testo di qualsiasi tipo - composta intenzionalmente in modo tale che, unendo le prime lettere di ogni capoverso, si ottiene un messaggio di senso compiuto. Esistono numerose varianti di questa semplice idea di base, come il testo che segue (il quale fu realmente inviato da una spia tedesca durante la seconda guerra mondiale):
================================================================== Apparently neutral's protest is thoroughly discounted and ignored. Isman hard hit. Blockade issue affects pretext for embargo on by products, ejecting suets and vegetable oils. ==================================================================
Considerando in sequenza la seconda lettera di ogni parola, si ottiene il messaggio:
============================== Pershing sails from NY June 1 ==============================
(Nota: in realtà c'è una "r" di troppo)
Le griglie di Cardano erano fogli di materiale rigido nei quali venivano ritagliati fori rettangolari a intervalli irregolari; applicando la griglia sopra un foglio di carta bianca, il messaggio segreto veniva scritto nei buchi (ciascun buco poteva contenere una o più lettere), dopodiché si toglieva la griglia e si cercava di completare la scrittura del resto del foglio in modo da ottenere un messaggio di senso compiuto, il quale poi veniva inviato a destinazione.
Applicando sul foglio una copia esatta della griglia originaria, era possibile leggere il messaggio nascosto.
Gli inchiostri invisibili (o inchiostri simpatici) sono sostanze che, in condizioni normali, non lasciano tracce visibili se usate per scrivere su un foglio di carta, ma diventano visibili (rivelando in tal modo la scrittura) se il foglio viene sottoposto a una fonte di calore. È così possibile scrivere il messaggio segreto negli spazi compresi tra le righe di un messaggio dall'aspetto innocuo, quest'ultimo scritto con un inchiostro normale. (Per accedere al messaggio segreto occorre letteralmente "saper leggere tra le righe"...). Le sostanze più usate a questo scopo sono molto comuni: succo di limone, aceto, latte, ma durante la seconda guerra mondiale sono state impiegate sostanze più sofisticate, come ad esempio gli inchiostri al cobalto, che possono essere resi visibili solo mediante l'uso di particolari reagenti chimici.
Un'altra tecnica molto usata dai nazisti durante la seconda guerra mondiale è quella dei micropunti fotografici: si tratta di fotografie della dimensione di un punto dattiloscritto che, una volta sviluppate e ingrandite, possono diventare pagine stampate di buona qualità.
Questi pochi ma significativi esempi dovrebbero essere sufficienti a chiarire il concetto di steganografia, il quale viene spesso confuso, in prima analisi, con quello di crittografia. Per rendere più esplicite le differenze tra questi due concetti possiamo osservare che, mentre nel caso della crittografia è consentito al nemico di rilevare, intercettare e modificare i messaggi senza però avere la possibilità di violare le misure di sicurezza garantite dallo specifico sistema crittografico (cioè senza poter accedere all'informazione vera e propria e quindi leggerne il contenuto), l'obiettivo della steganografia è invece quello di nascondere un messaggio dentro un altro messaggio, dall'aspetto innocuo, in modo che il nemico non possa neppure rilevare l'esistenza del primo messaggio.
Ciò che caratterizza la steganografia, come si è visto, è l'esistenza di un secondo messaggio facilmente percepibile, il cui senso è generalmente del tutto disgiunto da quello del messaggio segreto che esso contiene. Nel seguito si indicherà questo secondo messaggio come messaggio contenitore o più semplicemente contenitore.
Come si può facilmente immaginare, le nuove tecnologie e in particolar modo i sistemi per l'elaborazione dell'informazione, hanno consentito anche nel caso della steganografia la progettazione di nuove tecniche, sempre più sofisticate, sicure e pratiche da usare. Questo capitolo cercherà proprio di esporre le idee che stanno alla base dei più diffusi programmi per computer che consentono di steganografare un messaggio dentro un altro. Le prime definizioni proposte riguardano l'origine del file contenitore: alcune tecniche - probabilmente le più numerose - come si vedrà consentono di "iniettare" il messaggio segreto dentro un messaggio contenitore già esistente, modificandolo in modo tale sia da contenere il messaggio sia da risultare, al livello al quale viene percepito dai sensi umani, praticamente indistinguibile dall'originale. Indichiamo l'insieme di queste tecniche con il termine steganografia iniettiva. Esistono tuttavia altre tecniche steganografiche che hanno capacità proprie di generare potenziali messaggi contenitori e utilizzano il messaggio segreto per "pilotare" il processo di generazione del contenitore. Per queste tecniche adottiamo il termine steganografia generativa. Alla fine del capitolo verranno passati in rassegna esempi di programmi di entrambi i tipi.
Secondo un sistema di classificazione diverso, le tecniche steganografiche possono essere ripartite in tre classi: steganografia sostitutiva, steganografia selettiva e steganografia costruttiva.
Le tecniche del primo tipo sono di gran lunga le più diffuse, tanto che in genere con il termine steganografia ci si riferisce implicitamente a esse. Tali tecniche si basano sulla seguente osservazione: la maggior parte dei canali di comunicazione (linee telefoniche, trasmissioni radio, ecc.) trasmettono segnali che sono sempre accompagnati da qualche tipo di rumore. Questo rumore può essere sostituito da un segnale - il messaggio segreto - che è stato trasfor mato in modo tale che, a meno di conoscere una chiave segreta, è indistinguibile dal rumore vero e proprio, e quindi può essere trasmesso senza destare sospetti.
Quasi tutti i programmi che sono facilmente reperibili si basano su questa idea, sfruttando la grande diffusione di file contenenti una codifica digitale di immagini, animazioni e suoni; spesso questi file sono ottenuti da un processo di conversione analogico/digitale e contengono qualche tipo di rumore. Per esempio, uno scanner può essere visto come uno strumento di misura più o meno preciso. Un'immagine prodotta da uno scanner, da questo punto di vista, è il risultato di una specifica misura e come tale è soggetta a essere affetta da errore.
La tecnica base impiegata dalla maggior parte dei programmi, consiste semplicemente nel sostituire i "bit meno significativi" delle immagini digitalizzate con i bit che costituiscono il file segreto (i bit meno significativi sono assimilabili ai valori meno significativi di una misura, cioè quelli che tendono a essere affetti da errori.) Spesso l'immagine che ne risulta non è distinguibile a occhio nudo da quella originale ed è comunque difficile dire se eventuali perdite di qualità siano dovute alla presenza di informazioni nascoste oppure all'errore causato dall'impiego di uno scanner poco preciso, o ancora alla effettiva qualità dell'immagine originale prima di essere digitalizzata. Per fissare meglio le idee, ecco un esempio concreto. Uno dei modi in cui viene solitamente rappresentata un'immagine prodotta da uno scanner è la codifica RGB a 24 bit: l'immagine consiste di una matrice MxN di punti colorati (pixel) e ogni punto è rappresentato da 3 byte, che indicano rispettivamente i livelli dei colori primari rosso (Red), verde (Green) e blu (Blue) che costituiscono il colore. In questo modello i colori possibili sono 224 = 16777216; i cosiddetti grigi sono i colori in cui i livelli di rosso, verde e blu sono coincidenti e quindi sono soltanto 256. Supponiamo che uno specifico pixel di un'immagine prodotta da uno scanner sia rappresentato dalla tripla (12, 241, 19) (si tratta di un colore tendente al verde, dato che la componente verde predomina fortemente sulle altre due); in notazione binaria, le tre componenti sono:
=============== 12 = 00001100 241 = 11110001 19 = 00010011 ===============
quelli che in precedenza abbiamo chiamato i "bit meno significativi" dell'immagine sono gli ultimi a destra, cioè 0-1-1, e sono proprio quelli che si utilizzano per nascondere il messaggio segreto. Se volessimo nascondere in quel pixel l'informazione data dalla sequenza binaria 101, allora bisognerebbe effettuare la seguente trasformazione:
============================== 00001100 --> 00001101 = 13 11110001 --> 11110000 = 240 00010011 --> 00010011 = 19 ==============================
La tripla è così diventata (13, 240, 19); si noti che questo tipo di trasformazione consiste nel sommare 1, sottrarre 1 o lasciare invariato ciascun livello di colore primario, quindi il colore risultante differisce in misura minima da quello originale. Dato che un solo pixel può contenere un'informazione di 3 bit, un'immagine di dimensioni MxN può contenere un messaggio segreto lungo fino a (3*M*N)/8 byte, per esempio un'immagine 1024x768 può contenere 294912 byte.
La tecnica appena descritta rappresenta il cuore della steganografia sostitutiva, anche se di fatto ne esistono numerose variazioni. Innanzitutto è ovvio che tutto quello che abbiamo detto vale non solo per le immagini, ma anche per altri tipi di media, per esempio suoni e animazioni digitalizzati. Inoltre - e questo è meno ovvio - lavorando con le immagini come file contenitori non sempre si inietta l'informazione al livello dei pixel, ma si è costretti a operare su un livello di rappresentazione intermedio; è questo il caso, per esempio, delle immagini in formato JPEG, nel quale le immagini vengono memorizzate solo dopo essere state compresse con una tecnica che tende a preservare le loro caratteristiche visive piuttosto che l'esatta informazione contenuta nella sequenza di pixel. Se iniettassimo delle informazioni in una bitmap e poi la salvassimo in formato JPEG, le infor mazioni andrebbero perdute, poiché non sarebbe possibile ricostruire la bitmap originale. Per poter utilizzare anche le immagini JPEG come contenitori, è tuttavia possibile iniettare le informazioni nei coefficienti di Fourier ottenuti dalla prima fase di compressione.
Esiste un altro caso interessante che merita di essere discusso, ed è quello dei formati di immagini che fanno uso di palette. La palette (tavolozza) è un sottoinsieme prestabilito di colori. Nei for mati che ne fanno uso, i pixel della bitmap sono vincolati ad assumere come valore uno dei colori presenti nella palette: in questo modo è possibile rappresentare i pixel con dei puntatori alla palette, invece che con la terna esplicita RGB (red, green and blue). Ciò in genere permette di ottenere dimensioni inferiori della bitmap, ma il reale vantaggio è dato dal fatto che le schede grafiche di alcuni anni fa utilizzavano proprio questa tecnica e quindi non potevano visualizzare direttamente immagini con un numero arbitrario di colori. Il caso più tipico è quello delle immagini in for mato GIF con palette di 256 colori, ma le palette possono avere anche altre dimensioni. Come è facile immaginare, un'immagine appena prodotta da uno scanner a colori sarà tipicamente costituita da più di 256 colori diversi, tuttavia esistono algoritmi capaci di ridurre il numero dei colori utilizzati mantenendo il degrado della qualità entro limiti accettabili. Si può osservare che, allo stesso modo in cui avviene con il formato JPEG, non è possibile iniettare infor mazioni sui pixel prima di convertire l'immagine in formato GIF, perché durante il processo di conversione c'è perdita di informazione (osserviamo anche che questo non vale per le immagini a livelli di grigi: tali immagini infatti sono particolarmente adatte per usi steganografici.) La soluzione che viene di solito adottata per usare immagini GIF come contenitori è dunque la seguente: si riduce il numero dei colori utilizzati dall'immagine a un valore inferiore a 256 ma ancora sufficiente a mantenere una certa qualità dell'immagine, dopodiché si finisce di riempire la palette con colori molto simili a quelli rimasti. A questo punto, per ogni pixel dell'immagine, la palette contiene più di un colore che lo possa rappresentare (uno è il colore originale, gli altri sono quelli simili ad esso che sono stati aggiunti in seguito), quindi abbiamo una possibilità di scelta. Tutte le volte che abbiamo una possibilità di scelta fra più alternative, abbiamo la possibilità di nascondere un'infor mazione: questo è uno dei principi fondamentali della steganografia. Se le alternative sono due possiamo nascondere un bit (se il bit è 0, scegliamo la prima, se è 1 la seconda); se le alternative sono quattro possiamo nascondere due bit (00 -> la prima, 01 -> la seconda, 10 -> la terza, 11 -> la quarta) e così via.
La soluzione appena discussa dell'utilizzo di GIF come contenitori è molto ingegnosa ma purtroppo presenta un problema: è facile scrivere un programma che, presa una GIF in ingresso, analizzi i colori utilizzati e scopra le relazioni che esistono tra di essi; se il programma scopre che l'insieme dei colori utilizzati può essere ripartito in sottoinsiemi di colori simili, è molto probabile che la GIF contenga infor mazione steganografata. Di fatto, questo semplice metodo di attacco è stato portato avanti con pieno successo da diverse persone ai programmi che utilizzano immagini a palette come contenitori, tanto che qualcuno ha finito per sostenere che non è possibile fare steganografia con esse.
Per mostrare quanto sia ampia la gamma di tecniche steganografiche, accenniamo a un'altra possibilità di nascondere informazioni dentro immagini GIF. Come abbiamo detto, in questo formato viene prima memorizzata una palette e quindi la bitmap (compressa con un algoritmo che preserva completamente le infor mazioni) consistente di una sequenza di puntatori alla palette. Se scambiamo l'ordine di due colori della palette e corrispondentemente tutti i puntatori ad essi, otteniamo un file diverso che corrisponde però alla stessa immagine, dal punto di vista dell'immagine il contenuto informativo dei due file è identico. La rappresentazione di immagini con palette è quindi intrinsecamente ridondante, dato che ci permette di scegliere un qualsiasi ordine dei colori della palette (purché si riordinino corrispondentemente i puntatori a essi). Se i colori sono 256, esistono 256! modi diversi di scrivere la palette, quindi esistono 256! file diversi che rappresentano la stessa immagine. Inoltre è abbastanza facile trovare un metodo per numerare univocamente tutte le permutazioni di ogni data palette (basta, per esempio, considerare l'ordinamento sulle componenti RGB dei colori). Dato che abbiamo 256! possibilità di scelta, è possibile codificare log(256!) = 1683 bit, cioè 210 byte. Si noti che questo numero è indipendente dalle dimensioni dell'immagine, in altre parole è possibile iniettare 210 bytes anche su piccole immagini del tipo icone 16x16 semplicemente permutando in modo opportuno la palette.
Dopo avere esaminato alcune tecniche steganografiche di tipo sostitutivo, discutiamo adesso i problemi relativi alla loro sicurezza. Innanzitutto premettiamo che le norme che valgono generalmente per i programmi di crittografia dovrebbero essere osservate anche per l'utilizzo dei programmi steganografici. Per ciò che riguarda le specifiche caratteristiche della steganografia, si tengano presente i seguenti principi: in primo luogo si eviti di usare come contenitori file prelevati da siti pubblici o comunque noti (per esempio, immagini incluse in pacchetti software, ecc.); in secondo luogo si eviti di usare più di una volta lo stesso file contenitore (l'ideale sarebbe quello di generarne ogni volta di nuovi, mediante scanner e convertitori da analogico a digitale, e distruggere gli originali dopo averli usati).
Come si è visto, queste tecniche consistono nel sostituire un elemento di scarsa importanza (in certi casi di importanza nulla) da file di vario tipo, con il messaggio segreto che vogliamo nascondere. Quello che viene ritenuto il principale difetto di queste tecniche è che in genere la sostituzione operata può alterare le caratteristiche statistiche del rumore presente nel media utilizzato. Lo scenario è il seguente: si suppone che il nemico disponga di un modello del rumore e che utilizzi tale modello per controllare i file che riesce a intercettare. Se il rumore presente in un file non è conforme al modello, allora il file è da considerarsi sospetto. Si può osservare che questo tipo di attacco non è per niente facile da realizzare, data l'impossibilità pratica di costruire un modello che tenga conto di tutte le possibili sorgenti di errori/ rumori, tuttavia in proposito esistono degli studi che in casi molto specifici hanno avuto qualche successo.
La steganografia selettiva e quella costruttiva hanno proprio lo scopo di eliminare questo difetto della steganografia sostitutiva. Vediamo di cosa si tratta.
La steganografia selettiva ha valore puramente teorico e, per quanto se ne sappia, non viene realmente utilizzata nella pratica. L'idea su cui si basa è quella di procedere per tentativi, ripetendo una stessa misura fintanto che il risultato non soddisfa una certa condizione. Facciamo un esempio per chiarire meglio. Si fissi una funzione hash semplice da applicare a un'immagine in forma digitale (una funzione hash è una qualsiasi funzione definita in modo da dare risultati ben distribuiti nell'insieme dei valori possibili; tipicamente questo si ottiene decomponendo e mescolando in qualche modo le componenti dell'argomento); per semplificare al massimo, diciamo che la funzione vale 1 se il numero di bit uguali a 1 del file che rappresenta l'immagine è pari, altrimenti vale 0 (si tratta di un esempio poco realistico ma, come dicevamo, questa discussione ha valore esclusivamente teorico). Così, se vogliamo codificare il bit 0 procediamo a generare un'immagine con uno scanner; se il numero di bit dell'immagine uguali a 1 è dispari ripetiamo di nuovo la generazione, e continuiamo così finché non si verifica la condizione opposta. Il punto cruciale è che l'immagine ottenuta con questo metodo contiene effettivamente l'informazione segreta, ma si tratta di un'immagine "naturale", cioè generata dallo scanner senza essere rimanipolata successivamente. L'immagine è semplicemente sopravvissuta a un processo di selezione (da cui il nome della tecnica), quindi non si può dire in alcun modo che le caratteristiche statistiche del rumore presentano una distorsione rispetto a un modello di riferimento. Come è evidente, il problema di questa tecnica è che è troppo dispendiosa rispetto alla scarsa quantità di informazione che è possibile nascondere. Ad ogni modo, alla fine del capitolo si proporrà un esempio di programma che implementa una steganografia di tipo generativo, utilizzando con successo l'idea di base della steganografia selettiva di nascondere le informazioni procedendo per tentativi.
La steganografia costruttiva affronta lo stesso problema nel modo più diretto, tentando di sostituire il rumore presente nel medium utilizzato con l'informazione segreta opportunamente modificata in modo da imitare le caratteristiche statistiche del rumore originale. Secondo questa concezione, un buon sistema steganografico dovrebbe basarsi su un modello del rumore e adattare i parametri dei suoi algoritmi di codifica in modo tale che il falso rumore contenente il messaggio segreto sia il più possibile conforme al modello. Questo approccio è senza dubbio valido, ma presenta anche alcuni svantaggi. Innanzitutto non è facile costruire un modello del rumore: la costruzione di un modello del genere richiede grossi sforzi ed è probabile che qualcuno, in grado di disporre di maggior tempo e di risorse migliori, riesca a costruire un modello più accurato, riuscendo ancora a distinguere tra il r umore originale e un sostituto. Inoltre, se il modello del rumore utilizzato dal metodo steganografico dovesse cadere nelle mani del nemico, egli lo potrebbe analizzare per cercarne possibili difetti e quindi utilizzare proprio il modello stesso per controllare che un messaggio sia conforme a esso. Così, il modello, che è parte integrante del sistema steganografico, fornirebbe involontariamente un metodo di attacco particolarmente efficace proprio contro lo stesso sistema.
A causa di questi problemi, la semplice tecnica iniettiva di base rimane quella più conveniente da usare. Se si hanno particolari esigenze di sicurezza, esiste sempre una strategia molto semplice e allo stesso tempo molto efficace: quella che consiste nell'utilizzare contenitori molto più ampi rispetto alla quantità di informazioni da nascondere. Per esempio, invece di utilizzare i bit meno significativi di tutti i pixel di un'immagine, si può giocare sul sicuro utilizzando solo un pixel ogni 10, o anche più, fino a rendere impossibile, a tutti gli effetti pratici, la rilevazione di una distorsione delle caratteristiche statistiche del rumore. Su questo punto si tornerà in seguito.
Resta da affrontare un'ultima questione molto importante. Abbiamo accennato all'eventualità che i dettagli di funzionamento di un sistema steganografico possano cadere nelle mani del nemico. In ambito crittografico si danno le definizioni di vari livelli di robustezza di un sistema, a seconda della capacità che esso ha di resistere ad attacchi basati su vari tipi di informazioni a proposito del sistema stesso. In particolare, i sistemi più robusti sono quelli che soddisfano i requisiti posti dal principio di Kerckhoff, che formulato in ambito steganografico suona più o meno così: la sicurezza del sistema deve basarsi sull'ipotesi che il nemico abbia piena conoscenza dei dettagli di progetto e implementazione del sistema stesso; la sola informazione di cui il nemico non può disporre è una sequenza (corta) di numeri casuali - la chiave segreta - senza la quale, osser vando un canale di comunicazione, non deve avere neanche la più piccola possibilità di verificare che è in corso una comunicazione nascosta.
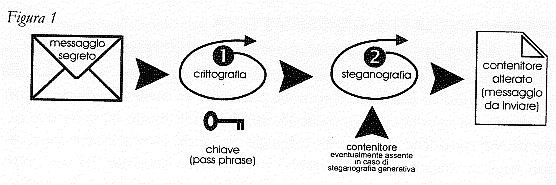
Se si vuole aderire a questo principio, è evidente che le tecniche esposte fin qui non sono ancora soddisfacenti per caratterizzare un sistema steganografico completo. Infatti, se i dettagli di implementazione dell'algoritmo sono resi di dominio pubblico, chiunque è in grado di accedere a eventuali informazioni nascoste, semplicemente applicando il procedimento inverso (nell'esempio visto, ciò si ottiene "riaggregando" i bit meno significativi dell'immagine). Per affrontare questo problema, è necessario introdurre una fase di pre-elaborazione del file segreto, che lo renda non riconoscibile - da parte del nemico - come portatore di informazioni significative. La soluzione più ovvia è quella di impiegare un sistema di crittografia convenzionale (per esempio, il PGP), il quale garantisce appunto l'inaccessibilità da parte del nemico al messaggio vero e proprio. Lo schema che ne risulta è riportato nella Figura 1.
(Se stai utilizzando un browser text-only clicca qui per visualizzare una versione ASCII della figura che segue)
La storia purtroppo non è finita qui, perché in questo meccanismo a due stadi il secondo processo è reversibile; in altri termini, chiunque può estrarre il file costituito dalle informazioni che fluiscono dal primo al secondo stadio. Poiché si presume che un crittoanalista esperto possa facilmente riconoscere un file prodotto da un programma di crittografia convenzionale, questo schema è ancora da considerarsi incompleto. Questo punto è di importanza fondamentale, perché rende definitivamente non valido il sistema steganografico, indipendentemente dal fatto che il contenuto dell'informazione segreta resti inaccessibile. Mentre il progettista di un algoritmo di crittografia assume che il nemico impiegherà tutte le risorse possibili per decrittare il messaggio, il progettista di un sistema steganografico deve supporre infatti che il nemico tenterà di rilevare la sola esistenza del messaggio. In altre parole, la crittografia fallisce il suo scopo quando il nemico legge il contenuto del messaggio: la steganografia invece fallisce quando il nemico si rende semplicemente conto che esiste un messaggio segreto dentro il file contenitore, pur non potendolo leggere. È opportuno quindi che il messaggio crittografato, prima di essere immerso nel contenitore, venga "camuffato" in modo da diventare difficilmente distinguibile da semplice rumore. A questo scopo, sono stati escogitati diversi metodi. Il più semplice è quello di eliminare dal file crittato da PGP tutte le informazioni che lo identificano come tale: il PGP, infatti, genera un file che rispetta un particolare formato, contenente, oltre al blocco di dati cifrati vero e proprio, informazioni piuttosto ridondanti che facilitano la gestione del file da parte dello stesso PGP (o di shell in grado di trattare con questo for mato). Esiste un piccolo programma, Stealth, capace di togliere - e di reinserire nella fase di ricostruzione - tutte le infor mazioni diverse dal blocco di dati cifrati. Il file che esce da Stealth appare come una sequenza di bit del tutto casuale, che è molto difficile distinguere da rumore ad alta entropia. Naturalmente, chiunque può provare ad applicare il procedimento inverso (prima Stealth per ricostruire l'intestazione, quindi il PGP), ma solo disponendo della chiave giusta si potrà alla fine accedere al messaggio in chiaro. In caso contrario non si potrà neppure capire se il fallimento sia dovuto al fatto di non disporre della chiave giusta oppure, verosimilmente, al fatto che l'immagine non contiene alcun messaggio nascosto.
Un metodo alternativo all'uso congiunto di PGP e Stealth è dato dall'uso di programmi espressamente progettati per trasfor mare un file in rumore apparente (per esempio, Wnstorm, White Noise Storm). Riassumendo, un sistema steganografico completo deve comprendere due fasi fondamentali: trasformazione del messaggio in chiaro in rumore apparente. Questa fase prevede l'uso di un sistema di crittografia convenzionale e quindi di un qualche tipo di chiave; iniezione nel (o generazione del) messaggio contenitore.
Per concludere, accenniamo a una tecnica iniettiva in cui le due fasi fondamentali sono intimamente intrecciate e vengono eseguite contemporaneamente. La tecnica è basata sul concetto di permutazione pseudocasuale. Come è noto, una permutazione è una corrispondenza biunivoca di un insieme in se stesso. Per esempio, se consideriamo l'insieme dei numeri interi compresi tra 0 e 4, la funzione P definita nel modo seguente:
================================================= P(0) = 2, P(1) = 1, P(2) = 4, P(3) = 0, P(4) = 3 =================================================
è una permutazione (per gli amanti delle lettere piuttosto che della matematica, il concetto di permutazione si avvicina a quello di anagramma; l'idea è la stessa: si tratta di "rimescolare" le componenti di un oggetto). Dato un insieme di M elementi, esistono M! possibili permutazioni dell'insieme: al crescere del numero degli elementi, il numero di tutte le possibili permutazioni cresce molto velocemente. Un generatore di permutazioni pseudocasuali è una funzione che prende in ingresso un numero M - la dimensione dello spazio da permutare - e una chiave segreta, e restituisce in uscita una permutazione dell'insieme {0, 1, 2, ..., M-1} apparentemente casuale, ma dipendente dalla chiave. La permutazione generata deve essere computazionalmente sicura, il che significa che non è possibile indovinare la permutazione senza conoscere la chiave.
La tecnica funziona nel modo seguente: supponiamo che i bit modificabili (per esempio, i bit meno significativi di un'immagine) del messaggio contenitore siano M e che i bit che compongono il messaggio segreto siano N (dove N<M; se fosse N>M, il contenitore non sarebbe abbastanza capiente). Scelta una chiave e indicando con P la permutazione di {0, 1, 2, 3, ..., M1} generata da M e da tale chiave, allora l'i-esimo bit del messaggio segreto viene sostituito al P(i)-esimo bit modificabile, e non all'i-esimo, come opererebbe una semplice tecnica sequenziale. In questo modo il messaggio segreto viene "sparpagliato" in modo apparentemente casuale all'interno del contenitore e l'unico modo per recuperarlo è quello di conoscere la chiave utilizzata per generare la permutazione.
Ma c'è di più: i bit potenzialmente utilizzabili sono M, ma di questi ne vengono effettivamente utilizzati soltanto N, i rimanenti M-N restano sicuramente inalterati; quindi, se N è strettamente minore di M, non è possibile neppure conoscere quali sono i bit effettivamente utilizzati tra i possibili candidati. L'idea cruciale è che la generazione della permutazione selezioni implicitamente il sottoinsieme dei bit utilizzabili che verranno effettivamente utilizzati (l'insieme individuato dagli indici {P(0), P(1), P(2), ..., P(N-1)}). Aumentando M, cioè la capienza del contenitore, tale sottoinsieme si apre a ventaglio riadattandosi in modo automatico nello spazio più ampio. Se N è molto minore di M, il messaggio segreto viene letteralmente "esploso" all'interno del contenitore. Come avevamo già osservato, all'utilizzo di un contenitore più ampio del necessario corrisponde un aumento del grado di sicurezza del sistema, purché i bit utilizzati non siano localizzati, ma distribuiti su tutto il contenitore. Questo risultato si ottiene in modo automatico con la tecnica delle permutazioni pseudocasuali.
Una buona raccolta di informazioni e di programmi relativi alla steganografia è stata creata, sotto forma di pagina Web, da Eric Milbrandt: il suo "Steganography Info and Archive" contiene un gran numero di collegamenti a documentazioni e programmi sparsi in tutto il mondo. Da tale pagina è anche possibile iscriversi alla mailing list utilizzata da Milbrandt per dare informazioni sulla disponibilità di nuovo software (o nuova documentazione) in ambito steganografico. La presente guida ha ovviamente un carattere puramente introduttivo, per avere ulteriori dettagli si rimanda alle documentazioni allegate ai vari programmi.
S-Tools è un pacchetto shareware composto da alcuni programmi steganografici per Windows: la versione 3 comprende tre utility per Windows 3.*, la versione 4 ne comprende due per Windows 95/NT. I programmi sono: ST-BMP, che consente di iniettare un file dentro immagini BMP a 24 bit o immagini GIF a 256 colori; ST-WAV che usa come contenitori file sonori in formato WAV; ST-FDD che nasconde le informazioni nello spazio non usato dei floppy disk (quest'ultimo è presente solo nella versione 3). La tecnica steganografica utilizzata è quella di base della steganografia sostitutiva (sostituzione del bit meno significativo), integrata con alcuni algoritmi di crittografia selezionabili dall'utente e dalla capacità di distribuire uniformemente le informazioni da nascondere nel contenitore, nel caso in cui questo sia più grande del necessario.
ST-FDD individua i settori non utilizzati di un floppy disk analizzando la FAT del dischetto, senza ovviamente modificarla; pertanto, dopo aver nascosto delle infor mazioni con questo sistema, occorre fare molta attenzione a non accedere nuovamente al floppy con i normali comandi DOS di copia file, poiché il DOS potrebbe allocare proprio i settori su cui è stata nascosta l'informazione, distruggendola senza alcuna possibilità di recupero.
I programmi hanno un'interfaccia grafica che ne rende particolarmente facile e intuitivo l'utilizzo; inoltre è disponibile un file di aiuto richiamabile selezionando l'opportuna opzione dall'Help Menu.
Si tratta senza dubbio di un ottimo strumento, anche se occorre fare molta attenzione all'utilizzo di contenitori come le immagini a 256 colori. Come si è visto, i metodi più diffusi per l'utilizzo di formati grafici con palette come contenitori, si basano su algoritmi per la riduzione del numero dei colori della palette, allo scopo di aggiungere colori simili a quelli rimasti, riservandosi in questo modo delle possibilità di scelta per ogni pixel dell'immagine. Dalla documentazione allegata a S-Tools possiamo constatare che anche ST-BMP funziona proprio in questo modo. Anche se non disponiamo dei sorgenti di questi programmi, possiamo fare un semplice esperimento per capire meglio come tutto questo possa influire sulla sicurezza del sistema.
L'archivio s-tools3.zip comprende, oltre ai programmi veri e propri, due file audio .wav e una immagine in formato GIF; dentro l'immagine (così come dentro uno dei file audio) è stato iniettato un messaggio, che è possibile leggere utilizzando i programmi inclusi nel pacchetto. Abbiamo innanzitutto verificato che l'immagine utilizzi effettivamente tutti i 256 colori presenti nella palette, quindi ci siamo fatti riordinare tali colori rispetto all'ordinamento sulle componenti RGB e ciò che abbiamo ottenuto è riportato nella Tabella 1.
=================================================================
tabella 1
142 16 10 57 19 30 182 85 79 209 142 138 224 196 197
143 16 10 56 18 31 183 85 79 208 143 138 225 196 197
142 17 10 57 18 31 190 100 96 209 143 138 224 197 197
143 17 10 56 19 31 191 100 96 208 142 139 225 197 197
160 18 10 57 19 31 190 101 96 209 142 139 78 110 198
161 18 10 168 40 32 191 101 96 208 143 139 79 110 198
160 19 10 169 40 32 190 100 97 209 143 139 78 111 198
161 19 10 168 41 32 191 100 97 180 144 148 79 111 198
142 16 11 169 41 32 190 101 97 181 144 148 78 110 199
143 16 11 168 40 33 191 101 97 180 145 148 79 110 199
142 17 11 169 40 33 180 104 100 181 145 148 78 111 199
143 17 11 168 41 33 181 104 100 180 144 149 79 111 199
160 18 11 169 41 33 180 105 100 181 144 149 24 78 204
161 18 11 144 50 52 181 105 100 180 145 149 25 78 204
160 19 11 145 50 52 180 104 101 181 145 149 24 79 204
161 19 11 144 51 52 181 104 101 214 162 158 25 79 204
148 20 14 145 51 52 180 105 101 215 162 158 24 78 205
149 20 14 144 50 53 181 105 101 214 163 158 25 78 205
148 21 14 145 50 53 98 70 104 215 163 158 24 79 205
149 21 14 144 51 53 99 70 104 214 162 159 25 79 205
162 22 14 145 51 53 98 71 104 215 162 159 228 212 214
163 22 14 104 50 56 99 71 104 214 163 159 229 212 214
162 23 14 105 50 56 98 70 105 215 163 159 228 213 214
163 23 14 104 51 56 99 70 105 218 172 170 229 213 214
148 20 15 105 51 56 98 71 105 219 172 170 228 212 215
149 20 15 172 62 56 99 71 105 218 173 170 229 212 215
148 21 15 173 62 56 198 120 116 219 173 170 228 213 215
149 21 15 172 63 56 199 120 116 218 172 171 229 213 215
162 22 15 173 63 56 198 121 116 219 172 171 240 230 228
163 22 15 104 50 57 199 121 116 218 173 171 241 230 228
162 23 15 105 50 57 198 120 117 219 173 171 240 231 228
163 23 15 104 51 57 199 120 117 224 184 182 241 231 228
162 26 16 105 51 57 198 121 117 225 184 182 240 230 229
163 26 16 172 62 57 199 121 117 224 185 182 241 230 229
162 27 16 173 62 57 54 60 118 225 185 182 240 231 229
163 27 16 172 63 57 55 60 118 224 184 183 241 231 229
162 26 17 173 63 57 54 61 118 225 184 183 248 246 246
163 26 17 180 72 66 55 61 118 224 185 183 249 246 246
162 27 17 181 72 66 54 60 119 225 185 183 248 247 246
163 27 17 180 73 66 55 60 119 184 176 186 249 247 246
112 20 20 181 73 66 54 61 119 185 176 186 248 246 247
113 20 20 180 72 67 55 61 119 184 177 186 249 246 247
112 21 20 181 72 67 124 104 132 185 177 186 248 247 247
113 21 20 180 73 67 125 104 132 184 176 187 249 247 247
112 20 21 181 73 67 124 105 132 185 176 187 250 250 250
113 20 21 182 84 78 125 105 132 184 177 187 251 250 250
112 21 21 183 84 78 124 104 133 185 177 187 250 251 250
113 21 21 182 85 78 125 104 133 224 196 196 251 251 250
56 18 30 183 85 78 124 105 133 225 196 196 250 250 251
57 18 30 182 84 79 125 105 133 224 197 196 251 250 251
56 19 30 183 84 79 208 142 138 225 197 196 250 251 251
251 251 251
=================================================================
Considerando i primi 16 colori della tabella, suddivisi in 4 gruppi di 4 ciascuno, possiamo facilmente osservare che ogni colore differisce in misura minima dagli altri dello stesso gruppo (Tabella 2).
=============================================== tabella 2 142 16 10 160 18 10 142 16 11 160 18 11 143 16 10 161 18 10 143 16 11 161 18 11 142 17 10 160 19 10 142 17 11 160 19 11 143 17 10 161 19 10 143 17 11 161 19 11 ===============================================
Inoltre, accorpando il primo gruppo con il terzo e il secondo con il quarto, otteniamo 2 gruppi di 8 colori, ciascuno dei quali è molto simile agli altri colori dello stesso gruppo. Questo procedimento può essere ripetuto per tutti gli altri colori della palette, ottenendo così 32 gruppi di 8 colori ciascuno. È facile capire, quindi, che S-Tools in una prima fase riduce effettivamente a 32 il numero dei colori utilizzati dall'immagine, dopodiché può sfruttare la ridondanza che si è venuta a creare nella palette per associare a ogni pixel tre bit di infor mazione, proprio come se si trattasse di un'immagine true color a 24 bit. Se si considera lo spazio di tutti i colori possibili come un cubo di lato 256 (sulle 3 dimensioni abbiamo i livelli di rosso, verde e blu, rispettivamente), si può vedere che i gruppi di cui abbiamo parlato non sono altro, in questo modello, che cubetti di lato 2 contenuti nel cubo completo (un cubo di lato l comprende un volume di l 3 colori.)
Senza entrare in ulteriori dettagli matematici, ci limitiamo a osservare che è possibile scrivere un semplice programma che, presa una immagine in ingresso, effettui un'analisi del tutto analoga a quella appena descritta: se è possibile ripartire l'insieme dei colori in gruppi di colori simili, allora è molto probabile che l'immagine contenga informazione steganografata. Sebbene l'algoritmo usato da ST-BMP per ridurre il numero dei colori sia effettivamente molto buono (nel senso che l'immagine ottenuta risulta poco distinguibile ad occhio nudo da quella originale), la conclusione più prudente è che non conviene usare per scopi steganografici questo programma (e naturalmente tutti i programmi che usano tecniche analoghe) con immagini GIF come contenitori. Occorre fare attenzione a non farsi trarre in inganno dal fatto che una preventiva crittazione del messaggio segreto possa comunque resistere a tutti gli attacchi noti: un sistema steganografico è da considerarsi debole se è possibile rilevare la presenza di infor mazione con un alto grado di attendibilità, indipendentemente dal fatto che sia possibile o meno accedere al contenuto vero e proprio dell'informazione. Lo stesso problema non si presenta utilizzando ST-BMP con immagini BMP a 24 bit, e neppure con gli altri programmi inclusi nel pacchetto.
Psteg è una libreria che implementa la tecnica delle permutazioni pseudocasuali discussa nel presente capitolo e quindi comprende soltanto il primo stadio di un sistema steganografico completo. La chiave usata dal generatore di permutazioni può essere una normale passphrase inserita dall'utente a tempo di esecuzione, oppure una chiave pubblica selezionata dai keyrings del PGP (se installato).
La libreria consente la creazione di programmi completi a partire da algoritmi di iniezione già esistenti, fornendo loro il supporto di funzioni che provvedono a comprimere preventivamente il file e a permutare i bit del file compresso, tenendo conto delle dimensioni del contenitore. Nel pacchetto sono inclusi due esempi già compilati per DOS, che utilizzano la libreria: CJPEG/DJPEG (si tratta dei classici programmi dell'Independent JPEG Group), ai quali è stata aggiunta una opzione per iniettare/estrarre un file in una immagine JPEG, e WAVPSTEG, che permette di iniettare/estrarre un file in un suono wave. Inoltre vengono date tutte le istruzioni necessarie per installare i sorgenti in C.
Vediamo un esempio di utilizzo dei programmi CJPEG/DJPEG. Supponiamo di voler iniettare nell'immagine superman.gif (ma potrebbe essere anche in for mato TARGA o in uno degli altri for mati supportati dal programma) il file luthor.txt in modo che solo Joe Lametta possa leggerlo; il comando da dare è:
================================================================== cjpeg -psteg lametta superman.gif superman.jpg < luthor.txt ==================================================================
In questo modo viene creato il file superman.jpg, che può essere inviato a Joe Lametta, il quale a sua volta può recuperare il file originale mediante il comando:
================================================================== djpeg -psteg lametta superman.jpg superman.pbm > lex.txt ==================================================================
Joe Lametta, dopo aver battuto correttamente la propria passphrase, potrà trovare il messaggio segreto nel file lex.txt.
Questo programma trasforma file di testo uuencodati (o ASCII-armoured del PGP) in una sequenza di frasi inglesi, implementando una steganografia di tipo generativo, dal momento che il testo generato non esiste in precedenza. Il programma trae ispirazione dai Mad Libs (improvvisazioni demenziali), un gioco che andava di moda un po' di anni fa negli Stati Uniti. Ogni Mad Lib era un raccontino breve del tutto banale, salvo il fatto di essere incompleto. In ogni racconto mancavano certe parole, lasciando una sequenza di spazi indicati solo con la parte del discorso (nome, verbo, aggettivo, avverbio, ecc.) sintatticamente richiesta per completare la frase. Chi conduceva il gioco chiedeva semplicemente agli altri di dire il primo sostantivo, verbo ecc. che venisse alla mente, inserendoli quindi nelle lacune del racconto. I giocatori non sapevano quale poteva essere il racconto, sapevano soltanto che dovevano fornire al conduttore certe parti del discorso. È facile immaginare che i racconti ottenuti in questo modo, sebbene fossero percepiti come sintatticamente corretti, suonavano del tutto ridicoli a causa delle incoerenze semantiche che si venivano a creare.
Il programma Texto funziona in modo del tutto analogo ai Mad Libs. Innanzitutto ecco un semplice esempio di utilizzo. Con un text editor si crei un file, superman.txt, contenente il messaggio segreto "Morte a Superman!", dopodiché lo uuencodiamo con le apposite utility ottenendo il file superman.uue. A questo punto, dando il comando:
=================== texto superman.uue ===================
quello che otteniamo in uscita è il seguente messaggio:
============================================================= The watch smartly places to the pathetic road. I mangle idle shoes near the plastic yellow stadium.Sometimes, frogs count behind solid windows, unless they're blue.Never lean fully while you're rolling through a wooden sticker.We familiarly train around green powerful rooms.While candles wanly grasp, the units. =============================================================
Il funzionamento è abbastanza semplice: l'autore del programma ha preventivamente preparato un file WORDS che contiene un piccolo dizionario di parole inglesi, suddivise in cinque categorie sintattiche, ciascuna contenente 64 parole. Le categorie sono: oggetti, luoghi, verbi, avverbi e aggettivi. Il file STRUCTS, anch'esso preventivamente preparato dall'autore, contiene una lista di frasi preconfezionate ma incomplete (template), contenenti "buchi" da riempire con opportune parole scelte dal precedente dizionario. Un esempio di template è il seguente:
================================================================== Sometimes, _THINGs _VERB behind _ADJECTIVE _PLACEs, unless they're _ADJECTIVE. ==================================================================
I "buchi" sono le parole che iniziano con il carattere "_" seguito da una delle cinque categorie sintattiche. Una volta scelto un template in modo casuale, il programma può ricavarne una vera e propria frase - più o meno sensata, come si è visto, ma sintatticamente corretta - riempiendo i buchi con parole scelte dal dizionario e appartenenti alle categorie specificate. Dato che per ogni categoria esistono 64 alternative, ogni scelta può codificare sei bit del file segreto. Per esempio, il template precedente contiene cinque "buchi" e quindi può codificare fino a 30 bit.
La fase di decodifica è implementata in maniera estremamente semplice: il testo viene scandito alla ricerca della prima parola contenuta nel dizionario; quando ne viene trovata una è possibile ricostruire i primi sei bit di informazione in base alla posizione occupata dalla parola nel dizionario: se la parola occupa la prima posizione, i bit estratti sono 000000, se è la seconda 000001, ecc., fino ad arrivare alla sessantaquattresima che codifica la sequenza 111111. Si continua con la ricerca della seconda parola, e così via, fino alla fine del testo (si noti che la semplicità di questa soluzione è resa possibile dal fatto che il dizionario e i template non contengono parole in comune; in caso contrario il programma dovrebbe essere in grado di effettuare una sorta di "pattern matching" tra i template e le frasi del testo.)
Si osservi che questo metodo funziona solo se il mittente e il destinatario usano lo stesso dizionario - stesse parole nello stesso ordine - mentre la lista dei template può essere modificata a piacere (purché si rispettino i vincoli discussi nella precedente nota). Questo significa che ognuno può divertirsi a creare diverse versioni dei file WORDS e STRUCTS - che sono semplici file di testo - con parole e template diversi e in diverse lingue, senza la necessità di modificare il programma eseguibile. Ciò che conta è che il mittente e il destinatario si accordino preventivamente sullo stesso file WORDS da usare.
Impiegando nella pratica questo sistema, ci si rende conto abbastanza presto di quali siano i suoi limiti: anche dotando il file STRUCTS di un numero molto elevato di template non si può fare a meno di notare il modo innaturale in cui si ripetono gli stessi schemi e le stesse parole, per non parlare della quasi totale assenza di senso compiuto che caratterizza i testi generati. È impensabile, quindi, che questo metodo non possa insospettire un eventuale controllore umano che abbia la possibilità di intercettare il messaggio contenitore.
Tuttavia un programmino come questo, pur nella sua semplicità, è in grado di mettere in crisi il tentativo di progettare un metodo automatico di attacco nei suoi confronti. Infatti le abilità necessarie per capire che un testo può essere generato da un programma come questo non sono ottenibili mediante semplici manipolazioni sintattiche (la semplice rilevazione di parole che occorrono varie volte non è sicuramente un criterio sufficiente), ma richiedono processi di percezione di alto livello del tutto comuni nelle persone e che tuttavia, al presente stato della ricerca in intelligenza artificiale, non sono ancora ben compresi né tantomeno disponibili sotto forma di modelli computazionali.
Resta da osservare che, per un corretto uso di questo programma, è necessario crittare preventivamente il messaggio segreto e trasformare il file crittato in rumore apparente, eliminando eventuali segni identificativi o applicando uno degli altri metodi che abbiamo discusso.
Possiamo muovere una critica a Texto: perché limitarsi ad accettare in ingresso solo file uuencodati (o ASCII-armoured del PGP)? Il fatto che gli insiemi di caratteri usati da questi tipi di file consistano esattamente di 64 elementi - un numero che nella pratica appare ragionevole adottare per le alternative di ogni categoria sintattica - non è una ragione valida, dal momento che qualsiasi file può essere visto come una sequenza lineare di bit. Di Texto sono anche disponibili i sorgenti in C, facilmente compilabili su qualsiasi piattaforma.
Stego è un altro esempio di programma che implementa una steganografia di tipo generativo, ma il suo funzionamento interno è radicalmente diverso da quello di Texto. Esso si basa sul concetto di funzioni mimiche, in particolare sull'idea di imitare lo stile di scrittura di un testo preso come modello di riferimento. Per fare questo, in una prima fase analizza il testo di riferimento costruendo un dizionario che contiene informazioni statistiche sulle sequenze di lettere che compaiono nel testo; in un secondo tempo, utilizza sia il file segreto che il dizionario per generare un testo avente le stesse caratteristiche statistiche del testo di riferimento. Il testo generato in questo modo, tuttavia, in genere non avrà un senso compiuto nemmeno al livello delle parole (si può parlare di pseudo-parole, cioè parole inesistenti che "suonano" come parole reali, o meglio come le parole che compaiono nel testo preso come modello). Tuttavia è anche possibile raccogliere informazioni sulle sequenze di parole invece che di lettere; in questo caso il testo sarà lessicalmente corretto, ma continuerà a non avere senso compiuto.
Il programma ha un'opzione molto interessante che consente di ottenere un testo che può essere decodificato senza disporre del testo di riferimento usato per creare il dizionario. Questa soluzione evita alle due parti che vogliono comunicare di doversi preventivamente accordare sul testo di riferimento (con tutti i problemi pratici che un tale accordo preventivo potrebbe comportare).
Vediamo più in dettaglio il funzionamento della fase di codifica attraverso le funzioni mimiche. Si prende un testo di riferimento e si misurano le occorrenze delle sequenze di testo lunghe N, con N scelto a piacere. Ad esempio con N=4 e il testo "questa è una questura", abbiamo:
==================== sequenza occorrenza "ques" 2 "uest" 2 "esta" 1 "sta " 1 "ta e" 1 "a e'" 1 ... "estu" 1 "stur" 1 "tura" 1 ====================
A questo punto si procede alla generazione del testo. Si considera il file da steganografare come uno stream di bit 0 e 1 distribuiti unifor memente da cui si estrae un bit alla volta. Supponendo il processo già a regime si guardano le ultime N-1 lettere generate del testo steganografato e si sceglie la lettera successiva in funzione dei bit letti dallo stream. Ad esempio con le N-1 lettere uguali a "est" ci sono due sequenze possibili:
================
"estu" 1 50%
"esta" 1 50%
-------------
2 100%
================
quindi si estrae un bit; se è 0 si genera la lettera "u", se è 1 si genera la lettera "a". Supponendo che sia il bit 1 le N-1 lettere diventano "sta" ed il processo si ripete. Naturalmente se ci sono più di due sequenze possibili il numero di bit codificati aumenta. Ciò si ottiene con una codifica simile a quella di Huffman. Ad esempio, le sequenze:
================ seq. perc. "estu" 5% "esta" 10% "estr" 10% "esti" 40% "esto" 20% "este" 15% ================
vengono partizionate in due gruppi in modo da avere circa il 50% da ciascuna parte:
======================= seq. perc. bit "esti" 40% 0 "estr" 10% 0 "esto" 20% 1 "este" 15% 1 "esta" 10% 1 "estu" 5% 1 =======================
e il processo viene ripetuto fino ad avere un codice per ogni sequenza, con l'accortezza di generare i codici solo se la partizione è circa 50%-50%.
Nel nostro esempio, ad "esti" (40%) ed "estr" (10%) la generazione di bit viene fermata e a entrambi i simboli viene assegnato il codice 0. Questo per evitare che nel testo steganografato ci siano troppe sequenze "estr" rispetto alle sequenze "esti", cioè un rapporto 1:1 invece che 1:4, rendendo il testo non più molto simile a quello di riferimento. L'effettivo simbolo viene invece scelto casualmente, ma dato che hanno tutti lo stesso codice, la decodifica rimane comunque possibile. Questo modo di procedere rende la codifica non deterministica, cioè codificando più volte lo stesso file si otterranno codifiche differenti ma equivalenti.
La decodifica senza dizionario deriva dall'associazione di una funzione di hash e della modalità di codifica attraverso le funzioni mimiche. Invece che codificare il file da steganografare viene codificato uno stream di bit pilotato e in contemporanea viene analizzato con la funzione di hash il risultato della codifica. Il processo viene ripetuto con tecnica backtracing finché la funzione di hash non generi come output il file da steganografare. Nella fase di decodifica basterà quindi riapplicare la funzione di hash per riottenere il file originale.
Per quanto riguarda il problema della sicurezza, le considerazioni relative a Texto sono valide anche per questo caso: prima si utilizza un sistema di crittografia convenzionale avendo cura di farne sparire le tracce; quello che si ottiene, poi, lo si manda in ingresso a Stego. Per le stesse ragioni già discusse a proposito di Texto, è molto difficile progettare un metodo di attacco automatico a questo sistema.
Per finire vediamo qualche esempio di utilizzo. Per prima cosa creiamo i file di tipo "dizionario" contenenti le informazioni statistiche che vogliamo conservare nei testi generati. Se il file divina.txt contiene il testo della Divina Commedia, i seguenti comandi creano i file divina.l5 e divina.w3
==================================== stego -il divina.txt 5 -w divina.l5 stego -iw divina.txt 3 -w divina.w3 ====================================
Il primo prende informazioni riguardo a tutte le sequenze di 5 lettere contenute nel testo della Divina Commedia, il secondo considera invece sequenze di 3 parole. Utilizziamo lo stesso messaggio segreto "Morte a Superman!" dell'esempio precedente, contenuto nel file superman.txt, e diamo il comando:
====================================================== stego -S 16 -d divina.l5 -f superman.tex superman.txt ======================================================
Il testo che otteniamo in uscita (file superman.tex) è il seguente:
====================================================================== Surge ad Arli, e' tolto. Vinci e staglie o difesa, pur ch'i' ne poi di Mirra sportero' guardi lieve cosa m'hanno ne' grembo e guarda col fiume fia che 'l ciel terza si` la ferme al romore dal fornisce e bella luce e' tonda tal colle sue vena e 'l maestro questa punge, qua nuovo li guasti ======================================================================
Utilizzando il secondo dizionario otteniamo:
====================================================== stego -S 16 -d divina.w3 -f superman.tex superman.txt ====================================================== ====================================================================== Temi e vederai l'altro disse, quella c'e' parte una persona li caldi e onde l'atterra torto e io fui del mal di Taumante, che le labbra mie vene e rompe i passi ad una, o ver lui che tiene ancor le due le sta come due si movono a Dio: 'Piu' mi trassi. Ed ei mi bagna. Io dicea con la man ======================================================================
si osservi che, a causa del non-determinismo nel processo di codifica, ripetendo più volte lo stesso comando, tipicamente si ottengono risultati diversi. Applicando ad entrambi i testi il comando:
========================================= stego -X 16 -f superman.out superman.tex =========================================
si ottiene nuovamente il messaggio originale (leggibile nel file superman.out). In questi due esempi abbiamo usato le opzioni che utilizzano la funzione di hash (-S e -X maiuscole); questo ha reso possibile la decodifica senza specificare un dizionario. La distribuzione di Stego comprende anche i sorgenti in C++, compilabili su diversi sistemi.
La disponibilità delle tecniche steganografiche discusse in questo capitolo ha una immediata conseguenza: dovunque esista un canale di comunicazione è impossibile controllare le informazioni che vi transitano. La sola disponibilità della crittografia convenzionale non implica l'impossibilità di esercitare una forma di controllo sul canale: si può pensare a casi reali in cui l'uso della crittografia non sia ben visto o sia addirittura proibito.
Da tutto quello che abbiamo visto, e considerando la semplicità con cui qualsiasi persona avente modeste capacità di programmazione è in grado di mettere a punto sistemi steganografici estremamente efficaci, si può concludere che la sola idea di "proibire l'uso della crittografia" è assai ingenua, poiché ignora completamente la reale natura delle informazioni. Allo stesso modo attuare una simile proibizione, per legge o regolamento interno, sarebbe del tutto inutile, data l'impossibilità pratica di controllare che il divieto venga effettivamente rispettato.
C'e' un solo modo, palesemente assurdo e praticamente impossibile, per proibire la privacy nelle comunicazioni: abolire del tutto e definitivamente qualsiasi comunicazione.