
L'exploit IPP è stato semplificato
La sicurezza e la riservatezza sono due componenti essenziali per un utente che si affaccia ad una rete, ma spesso sono messe in discussione. Nei prossimi capitoli viene affrontato il tema della gestione di log degli eventi come strumento efficace per scoprire accessi irregolari al nostro sistema.
Nel capitolo 1 vengono esposte le problematiche che ci portano alla necessità
della gestione dei log; come utilizzare i log dei firewall e come gestire i
vari log di un sistema multipiattaforma.
Quando colleghiamo un computer ad una rete sorgono molte problematiche legate
alla sicurezza. Piccole, medie e grandi aziende come pure singoli utenti, richedono
che i propri dati mantengano una certa riservatezza e siano inaccessibili da
persone non autorizzate. Questa riservatezza viene spesso messa in discussione
da hacker che possono prendere di mira server web, inviare malicious code o
virus, imbrattare siti web o ottenere accessi fraudolenti. Per ovviare a queste
problematiche è utile una corretta gestione dei log
Nel capitolo 2 sono evidenziati due exploit che gli hacker utilizzano per accedere
a sistemi senza autorizzazioni.
Il primo si connette al server web e l'applicazione invia una stringa che causa
overflow e quindi la connessione al file cmd.exe. Da qui l'hacker ottiene il
comando del sistema.
il secondo utilizza l'accesso all'account anonimo, da qui l'hacker è
in grado di scaricare un file ASP con il quale accedere ai privilegi di amministratore.
Vedremo come scoprire entrambi gli attacchi con un'attenta osservazione dei
log degli eventi.
I capitoli 3 e 4 danno una panoramica su come UNIX e APACHE gestiscono i log,
le directory e i file utilizzati, gli strumenti che permettono l'analisi e il
monitoraggio dei log, quelli che permettono la gestione dei file di log e la
loro archiviazione e stampa.
Per APACHE vengono separati e gestiti in modo diverso i transfer_log dagli error_log,
e viene analizzato il traffico web mediante strumenti e programmi (sia gratuiti
che a pagamento), viene inoltre data la possibilità di scegliere il formato
e i dati inseriti nei log.
Entrambi i capitoli racchiudono informazioni specifiche di configurazione e
di programmazione ed esempi per illustrare meglio il funzionamento di tali nozioni.
Infine nei capitoli 5, 6 e 7 sono riportati tre applicativi commerciali: GFI
LANguard S.E.L.M.; Security report della NEXA; ACP PROFILER.
Tutti e tre lavorano sui log degli eventi ma si caratterizzano per il tipo di
gestione che utilizzano.
Il primo si rivolge esclusivamente a sistemi Windows utilizzando tecnologia
microsoft come, ad esempio, database ODBC.
Il secondo applicativo dà la possibilità di inviare al portale
NEXA il file dei log per un'analisi e controlli successivi.
Il terzo applicativo utilizza la tecnologia XML e JAVA per rendersi facilmente
estensibile ed integrabile in ogni applicazione.
1.1 Problematiche di sicurezza
I server web Internet Information Services (IIS) sono molto popolari tra le
aziende commerciali, con oltre 6 milioni di installazioni in tutto il mondo.
Sfortunatamente, ciò li rende un obiettivo altrettanto popolare tra gli
hacker. Di conseguenza, ogni tanto, emergono nuovi exploit che mettono in pericolo
l'integrità e la stabilità del proprio server web IIS.
Per molti amministratori diventa difficile mantenersi al passo con le varie
patch di sicurezza rilasciate per IIS a fronte di ogni nuovo exploit, facilitando
le possibilità, per utenti pericolosi, di trovare su Internet un server
web vulnerabile. Trarre vantaggio da un exploit non è difficile, con
gli opportuni strumenti di cui dispongono gli hacker. Questi consentono all'hacker
teenager medio di attaccare facilmente e, persino controllare, il server web,
con la possibilità di penetrare nella rete interna.
In altri termini, non è molto difficile per soggetti esterni accedere
ad informazioni aziendali riservate. Peggio, non necessariamente gli hacker
sono teenager come si pensa comunemente: per esempio, dipendenti scontenti o
concorrenti dell'azienda possono avere le loro buone ragioni per penetrare in
zone confidenziali della rete.
Pochi attacchi di hacker sono immediatamente e davvero riconoscibili come tali.
La maggior parte degli attacchi non è facile da scoprire, poiché
molti intrusi preferiscono rimanere nascosti in modo da poter utilizzare il
server web manipolato come base di lancio di attacchi nei confronti di server
web molto più importanti o popolari. Oltre a danneggiare l'integrità
del proprio sito web, un tale utilizzo del server può rendere responsabile
l'azienda in caso di attacchi nei confronti di altre aziende.
Nel caso di trasmissione di malicious code o virus, o nel caso di tentato accesso
fraudolento, le aziende devono poter bloccare il traffico non autorizzato. La
maggior parte delle aziende utilizzano i firewall che, se propriamente aggiornati
e manutenuti, servono a bloccare il traffico illecito e a creare log dettagliati
per tutto il traffico in entrata ed in uscita.
Se analizzati correttamente, i log dei firewall possono evidenziare attacchi
di Denial of Service (DoS) o altre attività sospette. Tuttavia, poche
aziende analizzano questi log e anche quelle che lo fanno, lo fanno poco frequentemente.
Quindi, molti tentativi di attacco passano inosservati, dando agli hacker un'elevata
probabilità di superare la barriera rappresentata dai firewall.
La firewall log analysis è un'operazione complessa che richiede il controllo
simultaneo di migliaia di eventi. I processi automatizzati di oggi possono filtrare
la stragrande maggioranza degli eventi, identificando soltanto quelli che sono
abbastanza sospetti da richiedere un'ulteriore analisi da parte di un esperto.
L'analista distingue un attacco dal normale traffico e, nel caso di un attacco
certo, può cambiare proattivamente la firewall policy aggiornando tutti
i sistemi di network intrusion detection.
Quando vengono scoperte irregolarità in un file di log, molti MSSP (Managed
Security Service Provider) semplicemente informano il cliente dell'irregolarità
e suggeriscono l'azione preventiva da intraprendere. Tuttavia, senza un team
di esperti dedicati alla gestione dei firewall, spesso le aziende non sono in
grado di effettuare le opportune modifiche dei firewall. Ecco perché
la gestione remota delle firewall policy è una componente critica dei
servizi di sicurezza gestiti.
Il MSSP può effettuare le modifiche in un firewall per contrastare gli
attacchi che possono essere stati identificati dall'analisi di log. Esso può
anche applicare le patch software indispensabili per mantenere una buona situazione
di sicurezza. Per garantire l'efficienza di un firewall è fondamentale
che sia l'applicazione firewall sia il sistema operativo del server sul quale
opera siano continuamente aggiornati. Se uno di questi è trascurato,
il firewall può persino costituire uno svantaggio e mettere in pericolo
la sicurezza dell'intera rete.
I clienti dovrebbero mantenere il controllo sulle policy di sicurezza. Se un
cliente chiede modifiche alle policy di un firewall che il MSSP non ritiene
essere nella gamma delle ottimali misure di sicurezza, il MSSP dovrebbe lavorare
per trovare e applicare alternative in grado di far fronte alle richieste di
business del cliente, mantenendo contemporaneamente il livello di sicurezza
dell'azienda.
1.4 Gestione dei log sulla rete
La centralizzazione dei log di un sistema o più in generale di un'intera
rete è una parte importante che permette un'analisi centralizzata di
quello che succede ma da sola non basta. Spesso le tecnologie sono differenti,
implementate da prodotti differenti, multipiattaforma: ogni sistema ha il suo
meccanismo di log, la sua sintassi, i suoi strumenti di GUI e di amministrazione,
i suoi comandi di reportistica e in più sono completamente indipendenti
l'uno con l'altro.
Per una corretta ed esaustiva comprensione dei log e degli eventi che accadono
nella propria infrastruttura è necessario avere un sistema che sia in
grado di comprendere tutti i formati dei log, di analizzarli e di creare un
database degli eventi in cui questi vengano memorizzati uniformati in sintassi.
Questo consentirà agli amministratori di avere un meccanismo per porre
delle query che vadano ad interrogare un database nel quale sono presenti tutti
i log del sistema e inoltre consentirà loro di avere una risposta molto
più comprensibile su quello che è veramente accaduto.
Questo porta alla soluzione di due problemi fondamentali: non è più
necessaria la conoscenza delle sintassi e dei significati di migliaia di sigle
da parte di chi amministra; l'evento è immediatamente comprensibile senza
ulteriori ragionamenti o sforzi e quindi consente un'immediato intervento.
Un log è diverso da un evento: spesso in una rete è di fondamentale
importanza capire l'accadimento di un evento in base a centinaia di log provenienti
da altrettanti server o dispositivi di rete o applicazioni.
Un sistema in grado di avere delle politiche di riconoscimento e di correlazione
degli eventi è di fondamentale importanza per fare emergere situazioni
che altrimenti passerebbero senza alcun dubbio inosservate.
I computer con Microsoft Windows sono dotati di servizi di controllo elementari,
ma non riescono a soddisfare le esigenze aziendali del mondo reale (ossia, controllare
i computer con Windows in tempo reale, analizzare periodicamente l'attività
della sicurezza e mantenere un tracciato del controllo a lungo termine). Nasce
dunque l'esigenza di uno strumento per la scoperta d'intrusione basato sui log
e di analisi il quale può colmare le lacune di funzionalità dei
log della sicurezza di Windows, senza danneggiare le prestazioni, pur rimanendo
conveniente.
Come scoprire gli hacker sul server web
2.1 Strumenti di lavoro degli hacker
Esistono molti strumenti a disposizione degli hacker che vogliono "imbrattare" un sito web. Questi strumenti sono talmente semplici da utilizzare che persino qualcuno con nessuna esperienza precedente come hacker può imbrattare un server web in pochissimo tempo.
L'exploit Internet Printing Protocol (IPP)
Un programma che utilizza questo exploit è l'Internet Printing Protocol Exploit v.0.15 (si veda la figura). Si basa sul noto codice di exploit originale di un file di programma in C denominato "jill.c", reso pubblico da un hacker il cui soprannome era "dark spyrit". Quest'applicazione utilizza una vulnerabilità da buffer overflow dell'IPP su un server web IIS. Tutto ciò che l'hacker deve fare è digitare il nome del server web preso di mira (oppure un computer su cui sia installato IIS) e fare clic su "Connetti". Con la connessione, l'applicazione invierà la stringa vera che causa l'overflow dello stack, comportando l'esecuzione di un programma shell personalizzato e la connessione del file cmd.exe alla porta specifica dell'aggressore (quella predefinita è la n. 31337).
L'exploit IPP è stato semplificato
Questa è in grado di aggirare configurazioni di firewall tipiche ed altre misure di sicurezza simili. Una volta fatto questo, l'hacker ottiene una riga di comando e un accesso al sistema, da cui potrebbe portare avanti una serie di attività che un amministratore non avrebbe certamente autorizzato, come l'accesso a database che potrebbero contenere dati relativi a carte di credito ed altre informazioni confidenziali.
Gli exploit di UNICODE e CGI-Decode
L'exploit di Unicode attraverso Internet Explorer
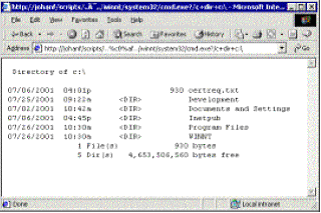
Altri due exploit preferiti dai defacer sono costituiti dagli exploit di UNICODE e CGI-Decode. In questo caso, l'hacker può semplicemente utilizzare il browser stesso per fare qualsiasi cosa sulla macchina target su cui sia installata una versione priva di patch di IIS. Tutto quello che serve è Internet Explorer ed una "stringa magica" per eseguire qualsiasi cosa sotto l'account anonimo dell'IIS. La schermata precedente illustra il "riversamento" della directory di C:\ del server IIS nel browser web stesso! Non si tratta che di un piccolo esempio che dimostra come l'hacker può ottenere accesso al disco rigido del proprio server web. L'accesso è limitato inizialmente alle autorizzazioni utente dell'account utente anonimo IIS (IUSR_nomedelcomputer). Quando l'hacker ha accesso all'account anonimo IIS, è in grado di scaricare facilmente un file ASP, con quale può a sua volta accedere a privilegi di amministratore di sistema. Un'azione del genere gli darebbe accesso totale al computer manipolato, vale a dire, l'hacker potrebbe fare tutto ciò che vuole.
Applicazioni personalizzate
Alcuni gruppi di cracker di siti web preferiscono produrre le proprie applicazioni per automatizzare il processo di "imbrattamento" di un sito web.

IIS Stom di m0sad
Uno di quesrti gruppi è M0sad, un'unità hacker israeliana che ha sviluppato e rilasciato uno strumento di hacking denominato IIS Storm v.2. Strumenti del genere conferiscono capacità da hacker complete sia ad hacker esperti sia ad hacker inesperti. IIS Storm permette inoltre agli utenti di nascondere il loro IP originale mediante proxy anonimi e di sostituire facilmente con proprie pagine HTML personalizzate file del sito web preso di mira. PoizonB0x, un altro noto gruppo di auto-proclamati "cyber-terroristi" e "guerrieri della rete", ha realizzato iisautoexp.pl, uno strumento automatico che gestisce tutto il lavoro "pesante" necessario per ottenere l'accesso ed eseguire operazioni di defacing. Per imbrattare un sito web, tutto quello che gli utenti malintenzionati devono fare è dare il nome del sito web allo script ed eseguirlo. Se il sito web è vulnerabile ad attacchi (se, cioè, non è munito delle opportune patch), la pagina iniziale (index.htm, default.htm, default.asp o sue varianti) viene cambiata in "PoizonB0x Ownz YA". In questo modo, gli hacker possono creare file di batch con i nomi dei siti web presi di mira, realizzando un imbrattamento di massa di server web IIS. Questo script può essere adattato ed eseguito sia su macchine Window sia su macchine UNIX. Sapere che il server web è stato attaccato è facile se la propria pagina web è modificata. Tuttavia, molti hacker installano furtivamente un Trojan per sottrarre dati in modo illegale o eseguire altre attività pericolose. Faranno in modo da non lasciare alcuna traccia del loro passaggio.
2.2 Scoperta di intrusione mediante monitoraggio di file di sistema
Allora, come ci si può proteggere da una tale possibile offensiva di
attacchi? Ebbene, quasi tutti gli strumenti di exploit per server IIS fanno
uso di uno o più file di sistema. Controllando l'attività di questi
file in tempo reale, un amministratore può cogliere l'hacker con le mani
nel sacco. Gli hacker utilizzano spesso i seguenti file di sistema:
1. cmd.exe: si tratta del programma di emulazione della riga di comando di Windows;
da qui gli utenti sono in grado di amministrare il server
2. ftp.exe: riga di comando client FTP disponibile con tutte le piattaforme
Microsoft
Windows; gli hacker la usano per ottenere i file della macchina server di cui
hanno bisogno tramite il server FTP remoto
3. net.exe: questo programma consente l'amministrazione della macchina, sotto
l'account di sistema; gli hacker possono utilizzare questo strumento per creare
utenti e gruppi backdoor, avviare e arrestare servizi, accedere alle altre macchine
della rete ed altro.
4. ping.exe: gli hacker possono usare il server dell'azienda presa di mira insieme
ad
altri server vulnerabili per eseguire ping contro un host mirato, creando così
un
attacco di tipo DDoS (Distributed Denial of Service) sul target.
5. tftp.exe: alcuni hacker lo preferiscono a ftp.exe e lo utilizzano per ottenere
i file di
cui necessitano per penetrare ulteriormente nel server IIS.
Quando un cracker esegue cmd.exe utilizzando l'exploit di UNICODE, esso è
in realtà eseguito dall'Internet Guest Account (IUSR_nomemacchina). Poiché
tale utente non ha attività che eseguono questo file, un monitor dei
log degli eventi di tutta la rete è in grado di registrare tutti gli
eventi in cui questo account esegue cmd.exe. In questo modo può immediatamente
informare l'amministratore dell'intrusione.
Gli attacchi di buffer overflow, invece, ottengono l'account di amministratore
di sistema. Ciò significa che da qui, l'utente malintenzionato, che si
è già introdotto nella macchina, è in grado di cambiarsi
in qualsiasi altro utente e, sostanzialmente, fare tutto quello che lo stesso
sistema operativo è in grado di fare. Tuttavia, se il monitor dei log
viene abilitato al controllo di cmd.exe e a registrare ogni volta che l'account
di amministratore ha accesso a questo file, l'amministratore di rete sarà
in grado di rilevare detta attività, perché, per cambiarsi in
un altro utente, gli strumenti fanno uso della riga di comando stessa.
3.1 Syslog e i log dei sistemi Unix
Molto spesso ci si ritrova a diagnosticare problemi, capire perchè una
applicazione non parte o eseguire blandi compiti di reverse engineering sul
funzionamento di parti del sistema.
La prima fonte da consultare per ogni operazione di troubleshooting sono i log,
file di testo che tengono traccia di errori e particolari azioni eseguite dal
sistema, come il cambiamento di una password, il login di un certo utente o
il messaggio di errore di una applicazione.
I log del sistema vengono generalmente scritti in directory come /var/log e
var/adm o dove definito nei file di configurazione dei singoli programmi.
In quasi tutti i sistemi Unix il demone syslogd si occupa della gestione dei
log tramite il file di configurazione /etc/syslog.conf.
Le recenti distribuzioni Linux utilizzano sysklogd, una versione evoluta di
syslogd che gestisce anche il logging del kernel (tramite il demone klogd).
Sono inoltre disponibili versioni modificato o più sicure di syslog.
L'equivalente su Windows dei log Unix sono gli eventi.
Logwatch e' uno strumento che permette l'analisi e il monitoraggio dei log.
E' molto semplice, versatile e flessibile in quanto permette di impostare il
servizio che si vuole monitorare, il livello di monitoraggio, filtri customizzabili
per il matching di pattern, periodi di tempo specifici ecc...
Oltre a questo e' possibile settare una mail a cui inviera' il report o un file
dentro il quale salvarli.
I file e le directory principali di logwatch sono generalmente:
/etc/log.d/conf/logwatch.conf: file di configurazione di logwatch;
/etc/log.d/conf/services/: directory che contiene i file di configurazione per
i diversi servizi i cui log possono essere processati da logwatch;
/etc/log.d/conf/logfiles/: directory che contiene i file di configurazione per
i file contenenti i log di diversi servizi;
/etc/log.d/scripts/shared/: directory che contiene i filtri comuni per i servizi
o logfiles;
/etc/log.d/scripts/logfiles/: directory che contiene i filtri specifici per
logfiles particolari;
/etc/log.d/scripts/services/: directory che contiene i filtri attuali per i
vari servizi.
Logwatch viene tipicamente schedulato in crontab per eseguire dei controlli
periodici sui log di sistema ed inviarne il report via mail.
3.3 logrotation e archiviazione dei log
La gestione e l'analisi dei log è un'attività sistemistica che
richiede le sue attenzioni.
Su macchine ad alto traffico, o sotto attacco DOS o con particolari problemi
ricorrenti, le dimensioni dei log possono crescere a dismisura in pochissimo
tempo, fino a saturare il file system.
Per questo motivo è sempre consigliabile montare la directory /var, dove
generalmente risiedono i log, in una partizione indipendente, che, anche se
riempita, non blocca il funzionamento del sistema.
E' inoltre importante poterli gestire, ruotandoli ad intervalli fissi e compattando
i log vecchi, preparandoli per un'archiviazione.
Su molte distribuzioni Linux è incluso Logrotate, un'applicazione che
semplifica l'amministrazione dei log, permette di comprimere, rimuovere ed inviare
il log via mail oltre a eseguire una rotazione di file con vari criteri.
Il file di configurazione è /etc/logrotate.conf
In sistemi che usano RPM , solitamente, le regole di gestione dei singoli log
sono inserite nella directory /etc/logrotate.d/.
Generalmente gli script che eseguono logrotate sono inseriti nel crontab e di
default sono configurati per gestire i log standard di sistema.
Il vantaggio di simili programmi è quello di sollevare l'amministratore dalla noiosa e insidiosa pratica di gestione e archiviazione dei log, che se non automatizzata può portare a spiacevoli conseguenze quali file system riempiti al 100%, file di log enormi, perdita di dati e simili contrattempi.
3.4 Colorize: visualizzazione colorata dei
log
L'utility colorize permette di visualizzare con sintassi colorata i file di
log.
Colorize è un piccolo script, di Karaszi Istvan e rilasciato sotto GPL,
scritto in linguaggio Perl, che permette di visualizzare i log, con una sintassi
colorata in modo da renderli più facilmente leggibili. Requisito di sistema
il modulo Perl Term::ANSIColor.
DOWNLOAD
E' possibile eseguire il download dal sito dell'autore:
Wget http://colorize.raszi.hu/downloads/colorize_0.3.4.tar.gz
SCOMPATTAZIONE E INSTALLAZIONE
Una volta scaricato lo script è sufficiente scompattarlo:
tar xvfz colorize_0.3.4.tar.gz
A questo punto è sufficiente copiare l'utility in una directory presente
nel PATH di sistema, ed il file di configurazione in /etc:
cp colorize /usr/bin/
copia dello script
cp colorizerc /etc/
copia del file di configurazione globale
Infine l'utility puo' essere utilizzata tramite pipe o altri metodi di redirezione
di input/output:
less /var/log/messages | colorize
colorize < /var/log/sudo.log
3.5 Configurare syslog per il jogging da router
CISCO
Per loggare su un syslog server Linux/Unix i log di un Cisco si deve intervenire
sia sul router che sul server.
Su Cisco configurare lo IOS (conf term) per definire il syslog server (qui 10.0.0.20):
logging server 10.0.0.20
logging facility local2
logging trap 7 (opzionale, imposta il logging a livello 7: debug)
Sul syslog server Unix/Linux fare partire syslog con l'opzione di logging via
rete (senza questo il syslogd non accetta messaggi via rete):
syslogd -r
e configurare /etc/syslog.conf per accettare i messaggi dal cisco (facility
local2):
local2.* /var/log/cisco.log
La porta usata per il syslog via rete è la 514 UDP.
Considerare che syslog è un protocollo estremamente vulnerabile (accetta
qualsiasi informazione, senza verificare contenuto o sorgente). E' opportuno
limitare agli IP che servono (con packet filtering di vario tipo) l'accesso
alla porta 514 di un syslog server.
Incrementare la sicurezza in un sistema operativo gnu/linux significa anche
analizzare e gestire paranoicamente i log.
Ciò significa che se non vogliamo perdere d'occhio tutto quello che accade
sul nostro sistema, anche dopo un eventuale attacco informatico, dobbiamo salvare
on-the-fly (al volo) i log su un dispositvo fisico esterno alla memoria del
pc, che potrebbe essere manomessa. Quindi una cosa buona e giusta, sarebbe quella
di stampare al volo tutto quello che succede sulla nostra macchina.
Certamente, ci vuole tanta carta e una buona stampante (anche vecchia) che stampi
a modulo continuo. Ecco un esempio per tener d'occhio i log del kernel in real
time:
tail -f /var/log/messages | grep -v "Inbound" > /dev/lp0
verrà stampato (/dev/lp0) in modalità raw tutto il cat del log
(/var/log/messages) on-the-fly (tail -f), filtrando gli eventuali inbound (grep
-v) del firewall attivo.
Il log management di Suse è simile a quello usato su Unix.
Il Syslog service, configurato nel file /etc/syslog.conf gestisce tutti i log
di sistema.
La configurazione di default è comune in alcune parti:
/var/log/messages riceve ogni log ad eccezione di quelli per la mail e per le
news;
/var/log/mail contiene tutti i log del sistema di mail, che sono divisi in diversi
file in base al livello di debug: mail.info mail.warn mail.err;
/var/log/news/ questa directory contiene tutti i log del servizio di news;
Altre impostazioni usate sono:
/var/log/localmessages riceve tutti i messaggi dalle local facilities (da local0
a local 7);
/dev/tty10 visualizza i warnings del kernel e tutti gli errori (Alt+F10 per
vederli).
/var/log/warn comprende tutti i warnings di sistema, errori e messaggi critici.
Syslogd usato nella tipica variante Linux supporta anche il logging del kernel
separato mediante il demone klogd.
Le facilities di Log rotation sono, per deafult, una maniera per rendere flessibile
logrotate, nel file di configurazione principale /etc/logrotate.conf è
configurato per includere tutte le configurazioni nella directory /etc/logrotate.d/.
Le impostazioni di default forniscono una rotazione settimanale per un totale
di 4 settimane, ma la configurazione include per i singoli servizi (apache,
samba, squid, fetchmail etc) un metodo per la rotazione dei logs quando questi
raggiungono una fissata dimensione e restringe a 99 i files di log archiviati.
Altri interessanti log sono:
/var/log/update-messages visualizza messaggi su update di packages;
/var/log/SaX.log /var/log/XFree86.0.log /var/log/kdm.log tutti forniscono (similarmente)
logs sul sistema X Window;
/var/log/boot.msg è l'insieme dei log dei servizi di sistema e del kernel
relativi all'ultimo boot;
/var/log/YaST2/ questa directory contiene tutti i log di YaST.
Se viene installato il package sysreport è possibile trovare i log sar
nella directory /var/log/sa/.
E' l'applicazione inclusa in diverse distribuzioni Linux per la gestione dei
log di sistema.
Logrotate permette di comprimere, rimuovere ed inviare via mail i file di log.
Ogni file può essere gestito in base criteri temporali (giornalmente,
settimanalmente, o mensilmente) oppure alle proprie dimensioni. Tipicamente
l'utilizzo di logrotate viene schedulato tramite il demone cron ed i file di
log da esso gestiti non vengono modificati più di una volta al giorno
salvo che il criterio sia basato sulla dimensione e logrotate avviato più
volte al giorno oppure che sia utilizzata l'opzione -f o --force e quindi logrotate
sia forzato a rielaborare i file di log.
Logrotate utilizza /var/lib/logrotate/status per tenere traccia dei log elaborati
e /etc/logrotate.conf per quanto riguarda la configurazione. Alcuni packages
installano informazioni relative alla rotazione dei log in /etc/logrotate.d/.
La sintassi è la seguente:
logrotate [-dvf?] [-m command] [-s statefile] [--usage]
-d: Abilita il debug mode. Questa azione implica anche l'utilizzo automatico
dell'opzione -v. In modalità di debug, non vengono apportati cambiamenti
ai log o al file di stato;
-v: Abilita il verbose mode ovvero visualizza informazioni durante la rotazione
dei log;
-f : Forza la rotazione dei log;
-?: Visualizza una breve guida in linea;
-m <comando>: Indica a logrotate quale comando utilizzare per inviare
via mail i log. Di default viene utilizzato /sbin/mail -s;
-s <state-file>: Indica a logrotate di utilizzare un file di stato diverso
da quello di default ovvero /var/lib/logrotate/status;
--usage: Visualizza le opzioni disponibili per l'applicazione.
E' il file di configurazione principale del demone syslog. Di solito ha questo
path in Unix vari ed è comodo consultarlo per verificare in fretta dove
il sistema scrive i suoi log.
Il file si puo' suddividere in due campi, suddivisi da uno o piu' spazi bianchi
o TAB:
SELECTOR: Diviso a sua volta in due parti separate da un punto: facility (identifica chi o cosa ha prodotto il messaggio) e priority(identifica il livello di priorita' del messaggio)
ACTION:Identifica il "logfile" dove vengono scritti i log corrispondenti. Oltre ad un normale file può essere un device coem la stampante o una console.
Analizziamo un esempio preso da una macchina RedHat Linux:
cat /etc/syslog.conf
Nel file /var/log/messages vengono loggati tutti i messaggi di livello informativo,
tranne quelli relativi alla posta (mail), all'accesso al sistema (authpriv)
e al cron
*.info;mail.none;authpriv.none;cron.none /var/log/messages
Tutti i log, di qualsiasi priorità, che hanno a che fare con l'accesso
al sistema, sono loggati in /var/log/secure
authpriv.* /var/log/secure
Tutti i log riguardanti la posta sono scritti in /var/log/maillog
mail.* /var/log/maillog
Tutti i log di comandi eseguiti in cron sono scritti in /var/log/cron
cron.* /var/log/cron
Tutti i log con priorità di emergenza vengono inviati ai terminali di
ogni utnete collegato al sistema
*.emerg *
I log relativi al boot (a cui è associata, su questo sistema la facility
local7) sono scritti in /var/log/boot.log
local7.* /var/log/boot.log
Alcune interessanti opzioni che si possono configurare su questo file sono
del tipo:
Tutti i log del sistema vengono inviati al syslog server chiamato pippo (il
nome deve essere risolvibile)
*.* @pippo
Tutti i movimenti di posta vengono scritti sulla console tty10
mail.* /dev/tty10
Tutti gli accessi al sistema sono stampati direttamente su una stampante locale
authpriv.* /dev/lp0
E' il file principale riguardante la configurazione di logrotate.
Attraverso il file di configurazione di logrotate è possibile definire
il comportamento dell'applicazione in due contesti: a livello globale (nella
prima parte del file) e a livello locale dove le regole ridefinite prevalgono
su quelle globali. Per ogni file di cui si vuole effettuare la rotazione è
necessario indicarne il percorso, al quale seguono tra parentesi graffe le direttive
di gestione.
Tra le direttive più utili:
- Criteri di rotazione
daily: Rotazione su base giornaliera;
weekly: Rotazione su base settimanale;
monthly: Rotazione su base mensile;
size <dimensione>: Rotazione in base alla dimensione;
notifempty: Non esegue la rotazione se il file è vuoto;
- Compressione
compress: Una volta archiviato il file di log, viene compresso tramite gzip;
compresscmd: Indica il programma da utilizzare al posto di gzip;
- Gestione File
create <mode> <owner> <group>: Immediatamente dopo la rotazione
viene creato un nuovo file con il nome identico al precedente. E' possibile
specificare, modalità di accesso, proprietario e gruppo;
copy: Crea una copia del file di log e non modifica l'originale che non viene
mai rimosso;
copytruncate: Utilizzata nel caso in cui non sia possibile chiudere il file
di log. Viene archiviata parte del file di log mentre ne viene eseguita una
copia;
olddir <directory>: I file di log vengono spostati nella directory indicata
prima di eseguire la rotazione;
- Configurazione
include <file o directory>: Legge il file oppure tutti i file della directory
indicata ed applica le direttive incontrate all'interno di essi. E' possibile
trovare include /etc/logrotate.d in quanto alcuni packages installano le proprie
istruzioni in questa directory;
- Operazioni Pre-log e Post-log
postrotate endscript: Tramite questo blocco di direttive è possibile
eseguire delle operazioni in seguito alla rotazione;
prerotate endscript: Tramite questo blocco di direttive è possibile eseguire
delle operazioni prima che avvenga la rotazione e solo se questa avrà
luogo;
Un esempio del file di configurazione:
#
# Parametri Globali
#
compress Abilita la compressione, di default con gzip, dei log dopo la rotazione
weekly La rotazione di default è stabilita con criterio temporale settimanale
ovvero ogni settimana viene creato un nuovo file di log
# Parametri Locali
/var/log/debug {
rotate 2 Indica che verranno mantenuti due file di log, in particolare uno per
ogni settimana. La rotazione in questo caso è settimanale in quanto la
direttiva di default non è stata ridefinita.
postrotate Blocco postrotate ovvero istruzioni eseguite in seguito alla rotazione
di un log. Possono esistere solamente all'interno di direttive locali
/sbin/killall -HUP syslogd Ferma e riavvia il logging da parte di syslogd in
modo che possa riprendere a lavorare sul nuovo file una volta effettuata la
rotazione del vecchio file di log
endscript Termine blocco postrotate
}
/var/log/faillog {
monthly Il criterio temporale viene ridefinito localmente e passa da settimanale
a mensile
rotate 2 Rotazione ogni 2 mesi
postrotate
/sbin/killall -HUP syslogd
endscript
}
/var/log/lastlog {
rotate 3 Rotazione ogni 3 settimane
postrotate
/sbin/killall -HUP syslogd
endscript
}
/var/log/maillog {
monthly
rotate 2 Rotazione ogni 2 mesi
postrotate
/sbin/killall -HUP syslogd
endscript
}
/var/log/syslog {
rotate 4 Rotazione ogni 4 settimane
postrotate
/sbin/killall -HUP syslogd
endscript
}
/var/log/messages {
rotate 2 Rotazione ogni 2 settimane
postrotate
/sbin/killall -HUP syslogd
endscript
}
/var/log/proftpd.log { Log ProFTPD Server
rotate 3 Rotazione ogni 3 settimane
postrotate
/sbin/killall -HUP syslogd
endscript
}
La configurazione e il comportamento di syslog su Solaris è comune a
quello di Linux e di altri Unix.
Il processo /usr/sbin/syslogd viene fatto partire allo startup tramite un normale
script di init, gestito da rc: /etc/init.d/syslog.
Il suo file di configurazione è /etc/syslog.conf e viene preprocessato
da M4:
*.err;kern.notice;auth.notice /dev/sysmsg
*.err;kern.debug;daemon.notice;mail.crit /var/adm/messages
daemon.info /var/adm/messages
*.alert;kern.err;daemon.err operator
*.alert root
*.emerg *
#auth.notice ifdef(`LOGHOST', /var/log/authlog, @loghost)
mail.debug ifdef(`LOGHOST', /var/log/syslog, @loghost)
ifdef(`LOGHOST', ,
user.err /dev/sysmsg
user.err /var/adm/messages
user.alert `root, operator'
user.emerg *
)
Notare le righe con la stringa ifdef, queste, tramite m4, vengono considerate
se il LOGHOST è associato ad un ip locale.
In /etc/hosts si può definire quale IP corrisponde a LOGHOST. Per esempio:
127.0.0.1 localhost loghost
172.17.0.10 server.dominio.it server
Un comando utile, sopratutto in script custom, per scrivere una entry direttamente
nel syslog è:
/usr/bin/logger [ -i ] [ -f file ] [ -p priority ] [ -t tag ] [ message ].
L'attività di logging è fondamentale per ogni servizio in esecuzione
su una macchina.
Su Apache oltre a fornire informazioni su eventi che riguardano il funzionamento
del servizio, nei log si tiene traccia di tutte le richieste http eseguite al
server web.
Il modulo mod_log_config gestisce tutte le attività di logging da Apache
1.3.5 in poi.
Generalmente su un server web si prvedono 2 diversi tipi di log: Error_log e
Transfer_log
4.1.1 i log di errore: Error_log
Contiene traccia di tutti gli errori incontrati da Apache. Di default viene
scritto in /server_root/logs/error.log ma la sua posizione può essere
configurata:
ErrorLog /var/log/httpd/error_log.
Ci può essere solo un ErrorLog nella configurazione generale, ma ne può
essere definito uno per ogni VirtualHost. Non si può impedire ad Apache
di loggare gli errori ma si possono evitare i tempi di scrittura su disco: ErrorLog
/dev/null.
E' possibile definire il livello di logging (in ordine di importanza: emerg
- alert - crit - error - warn - notice - info - debug) con la direttiva LogLevel:
LogLevel warn
E' inoltre possibile utilizzare syslog per il logging, di default Apache usa
la facility local7:
ErrorLog syslog
Ma si può definire una propria facility per gestire più facilmente
/etc/syslog.conf. Con l'esempio che segue si passano al syslog i messaggi di
errore utilizzando la facility apache:
ErrorLog syslog:apache
4.1.2 i log di accesso: Transfer_log
Qui vengono registrate tutte le richieste HTTP fatte al server dai client in
rete. Sono fondamentali per poter analizzare il traffico su un sito Web e vengono
allo scopo processati da appositi software di log analysys.
Il formato dei log di accesso può essere customizzato dall'utente ed
includere i dati che interessano.
Al contrario dei log di errore, i transfer log vanno esplicitamente configurati
e possono essere evitati.
L'impostazione di base del log viene fatto con la direttiva TransferLog ed è
nel Common Log Format (host ident authuser date request status bytes):
TransferLog /var/log/httpd/access_log.
Con la direttiva LogFormat si può scegliere cosa scrivere nel file di
log e si definisce il nome del tipo di log, che può poi venir utilizzata
con la direttiva CustomLog (nel caso che segue il nome del formato è
common).
LogFormat "%h %l %u %t \"%r\" %>s %b" common
CustomLog logs/access_log common
4.2 Analisi del traffico Web: strumenti e funzioni
Chiunque pubblica su Internet un suo sito web è interessato a sapere
quanti lo visitano, cosa guardano, da dove vengono e magari perchè lo
fanno.
Ogni server web logga, tiene traccia, di ogni file servito agli irrrequieti
browser suoi client.
Il tipo di informazioni loggate da un server web sono, per ogni file (immagine
o HTML) servito: data e ora della richiesta, IP del client remoto, client (browser)
utilizzato, referrer (URL della pagina che ha il link al file richiesto), nome
del file.
L'analisi dei log prodotti può essere automatizzata e analizzata per
ottenere statistiche interessanti e comprensibili.
Esistono in circolazione una moltitudine di log analyzers, programmi, gratuiti
o a pagamento, che analizzano i log di server Web vari e producono un output,
tipicamente in HTML, che con tabelle, schemi, grafici e statistiche riassumono
ed elencano innumerevoli dati sul traffico web generato da un sito.
Su Linux / Unix i più diffusi e validi programmi opensource o comunque
freeware per l'analisi del traffico web sono:
WEBALIZER: http://www.webalizer.org - Veloce, diffuso, con interesanti grafici
e statistiche
ANALOG: http://www.analog.cx/ - Statistiche dettagliate
AWSTATS: http://awstats.sourceforge.net/ - Ottima presentazione e grafici interessanti
Esistono moltissime alternative commerciali e anche diversi approccia all'analisi
del traffico web.
I tool qui presentati analizzano i log dei server web, altri tool utilizzando
delle proprie "sonde" all'interno di pagine Web, che registrano i
dati sui visitatori su un server centrale, alcuni inseriscono pezzi di codice,
per esempio in PHP, che logga su un database gli accessi.
Alcuni strumenti, infine, si adattano bene a grosse quantità di log anche
su sistemi distribuiti, altri sono più limitati, alcuni processano senza
problemi pagine dinamiche e i relativi accessi, altri lavorano bene solo su
pagine statiche.
4.3 Customizzare il formato dei log
Apache permette di scrivere nei propri log di accesso una serie di informazioni relative ad ogni richiesta fatta via HTTP.
Con la direttiva LogFormat si assegna un nickname al log e si decide il formato
dei dati che deve contenere.
La sintassi di base si riferisce al log di default, utilizzato dalla direttiva
TransferLog:
LogFormat formato
E' comunque possibile definire un nickname associato al formato impostato, che
può essere utilizzato con la direttiva CustomLog:
LogFormat formato nickname
I dati che possono essere scritti nel log sono vari e vengono identificati
con lettere o stringhe precedute dal simbolo %:
%b - Le dimensioni in byte del file trasferito (coincide con l'header Content-Lenght)
%f - Il nome del file e il path completo del documento richiesto
%h - L'hostname o, se non viene risolto, l'indirizzo IP del client
%a - L'indirizzo IP del client. E' uguale a %h se l'hostname non viene risolto
%A - L'indirizzo IP del server.
%l - Il nome dell'utente remoto, se fornito da un identd lookup (Poco utile
e inaffidabile)
%p - La porta TCP del server, a cui è arrivata la richiesta del client
(di solito 80)
%P - Il PID del child di Apache che ha gestito la richiesta
%r - La prima righa della richiesta HTTP,che contiene il metodo usato (GET,
POST...)
%s - Lo status code HTTP della risposta
%t - Date e ora della richiesta. Customizzabile con %{formato}t
%T - Il numero di secondi impiegati da Apache per processare la richiesta
%u - Il nome dell'utente eventualmente autenticato sul server
%U - L'URL richiesta dal client. Contenuta anche in %r
%v - Il canonical server name, come definito nella direttiva ServerName
%V - Il server name secondo quanto definito in UseCanonicalName
%{Variabile}e - Una variabile d'ambiente, così come definita dal server
%{Header}i - Un header http nella richiesta del client (esempi comuni: %{User-Agent}i
%{Referer}i )
%{Header}o - Un header http nella risposta del server (es: %{Last-Modified}o
)
%{Nota}n - Una stringa che può essere scambiata fra il core di Apache
e un modulo (esempio tipico, per il mod_usertrack: %{Cookie}n )
Un esempio tipico di log custom è incluso nella configurazione standard
di Apache:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\"
\"%{User-Agent}i\"" combined
che genera un log simile:
217.148.96.21 - - [07/Nov/2002:14:27:05 +0100] "GET /gfx/morecoresisproject.jpg
HTTP/1.1" 304 - "http://www.openskills.info/" "Opera/6.02
(Linux 2.4.17-GANDALF i686; U) [en]"
Una variazione sul tema, che cerca di raccogliere il maggior numero di informazioni
sui visitatori (ma di fatto difficilmente fornisce più informazioni di
un combined log) può essere:
LogFormat "%h %t \"%r\" %l %u \"%{Referer}i\" \"%{User-Agent}i\"
\"%{From}i\"" user
4.4 Log rotation e archiviazione dei log
La gestione e l'analisi dei log è un'attività sistemistica che
richiede le sue attenzioni.
Su macchine ad alto traffico, o sotto attacco DOS o con particolari problemi
ricorrenti, le dimensioni dei log possono crescere a dismisura in pochissimo
tempo, fino a saturare il file system.
Per questo motivo è sempre consigliabile montare la directory /var,
dove generalmente risiedono i log, in una partizione indipendente, che, anche
se riempita, non blocca il funzionamento del sistema.
E' inoltre importante poterli gestire, ruotandoli ad intervalli fissi e compattando
i log vecchi, preparandoli per un'archiviazione.
Su molte distribuzioni Linux è incluso Logrotate, un'applicazione che
semplifica l'amministrazione dei log, permette di comprimere, rimuovere ed inviare
il log via mail oltre a eseguire una rotazione di file con vari criteri.
Il file di configurazione è /etc/logrotate.conf
In sistemi che usano RPM , solitamente, le regole di gestione dei singoli log
sono inserite nella directory /etc/logrotate.d/.
Generalmente gli script che eseguono logrotate sono inseriti nel crontab e di
default sono configurati per gestire i log standard di sistema.
Altra applicazione che viene spesso usata per gestire, in particolare, i log
di Apache è Cronolog, che rende particolarmente semplice la segmentazione
di log in file diversi generati secondo unità di tempo configurabili
(es: un file diverso ogni giorno). E' particolarmente utile per gestire siti
ad alto traffico, in cui le dimensioni dei log tendono a crescere in modo spropositato.
Viene tipicamente usato come un filtro che riceve un log dallo standard input
e lo scrive in stdout su più diversi file, secondo le specifiche indicate
in un template. La sintassi di base è /path/cronolog [opzioni] template.
Per esempio:
/usr/sbin/cronolog /web/logs/%Y/%m/%d/access.log divide il log che riceve in
stdout in tanto diversi log in diverse directory secondo il criterio /web/logs/anno/mese/giorno/access.log,
con risultati tipo: /web/logs/2003/01/17/access.log.
Viene tipicamente usato in httpd.conf sfruttando la funzionalità di Apache
di inviare i log ad un comando esterno:
TransferLog "|/usr/sbin/cronolog /web/logs/%Y/%m-%d-access.log"
ErrorLog "|/usr/sbin/cronolog /web/logs/%Y/%m-%d-errors.log"
Crea un file di log diverso ogni giorno e li mette in directory divise per anno.
Il vantaggio di simili programmi è quello di sollevare l'amministratore dalla noiosa e insidiosa pratica di gestione e archiviazione dei log, che se non automatizzata può portare a spiacevoli conseguenze quali file system riempiti al 100%, file di log enormi, perdita di dati e simili contrattempi.
Una interessante e flessibile funzionalità del sistema di logging di Apache è la possibilità di inviare i dati di un log (sia un error log che un transfer log) ad un programma, tramite una normale pipe, invece che scriverli direttamente su un file.
Il programma che riceve il log in standard input potrà processarli e
scriverli in standard output secondo criteri assolutamente gestibili.
Va notato che il programma a cui si passano i log viene eseguito con i permessi
di Apache, quindi di root, per cui bisogna prestare attenzione ai possibili
rischi in termini di sicurezza.
Per questa funzione basta sostituire al nome del file la pipe e il nome del
programma (o la command line) a cui inviare i log.
Alcuni esempi possono essere illuminanti sulle enormi possibilità che
si aprono con questa funzione:
Compressione dei log on-the-fly:
CustomLog "|/usr/bin/gzip -c >> /var/log/access_log.gz" common
Reverse lookup sui client IP in quasi real-time, senza ritardare le risposte
del server come accade con la direttiva HostNameLookup:
CustomLog "|/usr/local/apache/bin/logresolve >> /var/log/access_log"
common
Esegue la rotazione automtica dei log ogni 24 ore (86400 secondi):
CustomLog "|/usr/local/apache/bin/rotatelogs /var/log/access_log 86400"
combined
Usando il tool cronolog si creano log mensili con nomi che contengono mese e
anno:
CustomLog "|cronolog /var/log/apache/DOMAIN/%Y/%Y-%m-access.log" combined
Si invia il log ad un proprio programma filtro.sh:
CustomLog "|/usr/local/bin/filtro.sh" combined
In un caso simile filtro.sh deve poter ricevere in STDIN dei dati, gestirli
e scriverli da qualche parte. Un esempio, che logga in un file a parte tutte
le richieste generate da worm come Nimda è questo:
#!/bin/sh
NIMDA_LOG=/var/www/httpd/nimda_log
NORMAL_LOG=/var/www/httpd/access_log
STRING=cmd.exe
while /bin/true;
do
read loginput
if [ `echo "$loginput" | grep -c $STRING ` == 1 ]
then
echo "$loginput" >> $NIMDA_LOG &
else
echo "$loginput" >> $NORMAL_LOG &
fi
done
4.6 Come non loggare le immagini su Apache
Una volta attivato, il trasfer loggin di Apache scrive una riga di log per ogni oggetto richiesto dai client. In siti con molto traffico o molte immagini può essere utile evitare di scrivere innumerevoli righe di log per tutte le immagini richieste e limitare il logging alle pagine html o simili.
Per farlo si possono usare alcune caratteristiche evolute della direttiva che
può eseguire controlli e decisioni sulla base delle variabili d'ambiente.
Queste variabili possono anche essere definite con la direttiva SetEnvIf disponibile
con il modulo mod_setenvif.
Di fatto per non loggare le immagini nel proprio log si può usare una
configurazione simile:
# Identifica negli URI i file .gif, .jpg e .png e li assegna alla variabile
images
SetEnvIf Request_URI \.gif$ image=gif
SetEnvIf Request_URI \.jpg$ image=jpg
SetEnvIf Request_URI \.png$ image=png
# Specifica di non loggare nel CustomLog le entry che matchano le imamgini
CustomLog logs/access_log common env=!image
4.7 Gestire la rotazione dei log su Apache
Il processo di ruotare i log su Apache, se fatto manualmente, richiede una certa attenzione, ma può essere automatizzato con script e tool specifici.
La procedura manuale, richiede un riavvio del server web.
Quando infatti si rinomina un file di log, Apache continua a loggare sullo stesso,
almeno fino ad un riavvio del servizio.
I comandi sono di questo tenore:
mv access_log access_log.old
mv error_log error_log.old
apachectl graceful
sleep 600
gzip access_log.old error_log.old
Si può anche fare un restart più rapido e brutale (apachectl restart)
che non aspetta la chiusura delle connessioni esistenti.
Questa operazione può essere automatizzata direttamente in configurazione
con filtri come Cronolog o il comando rotatelogs, distribuito con Apache (guardare
la parte sui Piped Log).
Alternativamente si possono usare programmi come LogRotate che gestiscono la
rotazione di ogni tipo di log.
GFI LANguard Security Event Log Monitor
GFI è un produttore di software per la sicurezza della rete, del contenuto
e per la messaggistica.
Vanta clienti come Microsoft, Shell Oil Lubricants, NASA, DHL, BMW e altri,
ed opera attraverso una rete mondiale di distribuzione. Inoltre GFI è
Microsoft Gold Certified Partner.
Uno dei prodotti di GFI è GFI LANguard S.E.L.M. il quale è munito
di un motore per l'analisi degli eventi della sicurezza che tiene conto del
tipo di evento di sicurezza, del livello di protezione di ciascun computer,
di quando l'evento è accaduto (fuori o durante l'orario di lavoro), del
ruolo del computer e del suo sistema operativo (stazione di lavoro, server o
controller di dominio). Basandosi su queste informazioni, GFI LANguard S.E.L.M.
classifica l'evento della sicurezza come critico, alto, medio o basso. In questo
modo è possibile affrontare velocemente gli eventi della sicurezza importanti
senza essere un esperto di log degli eventi e conoscere ingressi ed uscite di
ciascun evento di Windows.
Gestione dei log degli eventi su tutta la rete
Oltre all'analisi dei log degli eventi della sicurezza, GFI LANguard S.E.L.M.
può anche analizzare applicazioni, sistemi ed altri log degli eventi.
E' possibile eseguire una copia di sicurezza e cancellare automaticamente i
log degli eventi su tutte le macchine remote della vostra rete e visualizzare,
riportare e filtrare gli eventi su tutta la rete, invece che per singola macchina.
GFI LANguard S.E.L.M. memorizza tutti gli eventi in un database centrale, rendendo
semplice la creazione di rapporti su tutta la rete e la personalizzazione dei
filtri. Utilizzando regole personali, si possono creare avvisi di eventi basati
sull'ID dell'evento, su condizioni e su contenuti dell'evento. GFI LANguard
S.E.L.M. è in grado di analizzare i contenuti delle proprietà
degli eventi. Inoltre, consente di creare rapporti per una comprensione più
approfondita della rete.
5.2 Scoprire gli attacchi al server
Nel capitolo 2 sono state esaminate le modalità d'intrusione degli hacker,
ora gli amministratori possono quindi configurare i loro server e GFI LANguard
S.E.L.M. in modo da coglierli con le mani nel sacco.
Fase 1: configurazione del server web ai fini del controllo di oggetti
Per monitorare file usati comunemente, sui server web di Windows va abilitato
il controllo degli oggetti.
Se il server web è un server indipendente, per abilitare il controllo
degli oggetti bisogna:
1. Aprire Administrative Tools - Local Security Policy
2. Selezionare Local Policies e quindi Audit Policy
3. Fare doppio clic su Audit Object Access e selezionare Success and Failure.
Se il server web fa parte del dominio, bisogna abilitare il controllo dell'oggetto
come Domain Policy, invece che come semplice Local Policy. Tale operazione si
esegue con le stesse modalità, tramite Administrative Tools - Domain
Security Policy
Una volta compiuta tale operazione, bisogna specificare i file che si desidera
controllare. In questo esempio si vogliono controllare: cmd.exe, ftp.exe, net.exe,
ping.exe e tftp.exe.

Politica di controllo - accesso all'oggetto
Per abilitare il controllo di accesso all'oggetto, affinché registri
ogni tentativo di eseguire cmd.exe da parte dell'account di amministratore e
dell'account ospite di Internet, procedere come segue:
1. Fare clic con il tasto destro del mouse su cmd.exe e selezionare Properties
2. Quindi selezionare la scheda Security e fare clic su Advanced
3. Selezionare la scheda Auditing e fare clic su Add
4. È ora possibile inserire gli utenti che devono essere registrati quando
tentano di accedere all'Oggetto (cmd.exe): selezionare l'account di amministratore
5. Per abilitare il controllo completo su cmd.exe dell'account di amministratore,
selezionare tutte le opzioni Successful e Failed"
6. Premere OK, selezionare Add e ripetere l'operazione per l'account IUSR.
7. Questa procedura va eseguita per ftp.exe, net.exe, ping.exe e tftp.exe.
D'ora in poi l'accesso ai suddetti file da parte degli account
di amministratore o IURS verrà registrato nel log degli eventi della
sicurezza.

Configurazione del controllo
Fase 2: configurazione di GFI LANguard S.E.L.M. ai fini del monitoraggio
di questi eventi e dell'invio di messaggi di allerta all'amministratore
Dopo aver configurato il controllo di accesso ai file, bisogna configurare GFI
LANguard S.E.L.M. perché rilevi questi eventi della sicurezza:
1. Nel pannello di Configurazione di GFI LANguard S.E.L.M., assicurarsi che
il server web risulti elencato nel nodo dei computer da controllare.
2. Passare ora al nodo Event Processing Rules > Security Event Log > Object
Access.
Selezionare il nodo, fare clic su di esso con il tasto destro del mouse e selezionare
New > Processing rule
3. Fare clic su "aggiungi" e aggiungere gli eventi nn. 560 e 562.
Questi eventi identificheranno un'intrusione. Evento 560: Object Open - significa
che si è verificato un accesso all'oggetto (per esempio, è stato
eseguito cmd.exe) ed Evento 562: Handle Closed - significa che l'oggetto non
è più in uso (ad esempio, Cmd.exe è stato chiuso)
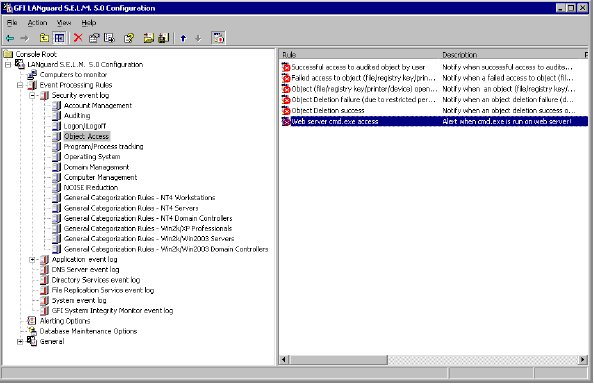
Console di configurazione di GFI LANguard S.E.L.M.
4. Per impostazione predefinita, tale regola verrà applicata su tutti
i computer monitorati da GFI LANguard SELM. Per specificare il solo server web,
aprire la scheda general e specificare il nome del computer server web. Specificare
inoltre una descrizione dettagliata.
5. Fare clic su OK per aggiungere la regola.

Creazione di una nuova regola di accesso all'oggetto
GFI LANguard S.E.L.M. monitorerà ora i server web alla ricerca di tali
eventi e qualora fosse eseguito il file CMD.exe, si verrà avvertiti immediatamente!
Fase 3: verifica dei nuovi ID
Una volta configurato quanto descritto in precedenza, è possibile testarlo.
Si può effettuare tale test creando un nuovo script ASP. Se le politiche
di controllo sono state impostate in maniera opportuna e si è abilitato
l'accesso all'oggetto sui file indicati, tale script creerà ed attiverà
una regola di controllo dell'oggetto. GFI LANguard S.E.L.M acquisirà
quindi dal log degli eventi della sicurezza l'evento generato e, in virtù
dell'esistenza di una regola corrispondente, invierà un messaggio email
di allerta all'amministratore per informarlo che si è verificato un accesso
al file cmd.exe.
5.3 Modalità di funzionamento di GFI
LANGuard S.E.L.M.
Panoramica sull'architettura
GFI LANguard Security Event Log Monitor (S.E.L.M.) realizza la scoperta d'intrusione
e i rapporti sulla sicurezza della rete mediante il controllo dei log degli
eventi di sicurezza di tutti i server Windows 2000/NT/XP/2003 e di tutte le
stazioni di lavoro dell'azienda. Avvisa in tempo reale di possibili intrusioni
ed attacchi.
Per garantire un'idonea integrazione con l'ambiente Windows nel suo complesso,
GFI LANguard S.E.L.M. utilizza la normale tecnologia Windows, ad esempio, Microsoft
Message Queuing (MSMQ), Microsoft Management Console (MMC), Microsoft Windows
Installer e Open Database Connectivity (ODBC). L'implementazione del controllo
su tutta la rete con GFI LANguard S.E.L.M. è molto semplice, non essendo
necessario installare il software su ogni computer che si desidera controllare.
L'amministratore installa GFI LANguard S.E.L.M. su un solo computer host e,
poi, si limita a registrare tutti gli altri sistemi da controllare. L'agente
di raccolta (Collector Agent) del prodotto utilizza quindi delle API di Win32
native per raccogliere eventi della sicurezza dai computer controllati. L'agente
di raccolta archivia gli eventi in un database Microsoft Access oppure su un
server Microsoft SQL. Tale architettura ODBC permette agli amministratori di
utilizzare strumenti di rapporti standard per creare rapporti personalizzati,
come il software Crystal Reports di Crystal Decisions. Poi, l'Alerter Agent
di GFI LANguard confronta gli eventi raccolti con una tabella di Regole di Categorizzazione
e classifica gli eventi come segue: a bassa sicurezza, media sicurezza, sicurezza
elevata o critici. L'Alerter Agent invia notifiche SMTP relative ad eventi critici
ad un indirizzo email configurato dall'amministratore (ad esempio un cercapersone),
in modo da informare immediatamente gli amministratori rispetto a possibili
tentativi d'intrusione. Per ogni computer controllato, l'amministratore può
specificare la frequenza di raccolta degli eventi, identificare le normali ore
di gestione e specificare il livello di sicurezza basso, medio o elevato di
un computer. L'impostazione dei livelli di sicurezza permette all'Alerter Agent
di considerare come più gravi gli eventuali eventi sospetti del sistema
che contengono informazioni sensibili o procedure, riducendo in questo modo
la quantità di falsi positivi riportati all'amministratore. Per eseguire
analisi regolari di tutti gli eventi della sicurezza, gli amministratori possono
servirsi del migliorato visualizzatore di eventi di GFI LANguard S.E.L.M. ovvero
del suo generatore di rapporti. Per garantire l'equilibrio tra consumo delle
risorse e avvisi tempestivi, gli amministratori possono specificare una frequenza
di raccolta diversa per ogni computer. L'Agente di archiviazione (Archiver Agent)
sposta periodicamente le attività precedenti dal database attivo ad un
archivio per la conservazione a lungo termine. GFI LANguard S.E.L.M. utilizza
la tecnologia MSMQ per mantenere un elevato livello di comunicazione tra i suoi
agenti interni.
Controllo in tempo reale e categorizzazione degli eventi di sicurezza
Il cuore della capacità di informativa intelligente di GFI LANguard
S.E.L.M. è costituito dal nodo delle Regole di elaborazione degli eventi
(Event Processing Rules) del programma snap-in della configurazione MMC di GFI
LANguard S.E.L.M.
Le regole di categorizzazione della sicurezza di GFI LANguard S.E.L.M. predefinite
sono progettate per aiutare il prodotto a riconoscere e informare l'amministratore
a proposito di eventi importanti, evitando contemporaneamente di disturbarlo
con falsi allarmi. Le regole consentono a GFI LANguard S.E.L.M. di segnali rivelatori,
quali eventi che avvengono in ore insolite e su computer dal livello di sicurezza
elevato. Eventi dalla bassa priorità non attivano un messaggio di allerta
immediato, ma sono sempre disponibili ai fini di un'analisi giornaliera o settimanale
da parte degli amministratori. GFI LANguard S.E.L.M. classifica ogni evento
come segue: a bassa sicurezza, media sicurezza, sicurezza elevata o critico.
Per farlo, il prodotto analizza l'ID dell'evento (per esempio, le ID degli eventi
correlati ad accessi non riusciti, blocchi di account, accessi a file) e le
caratteristiche del computer sul quale l'evento si è verificato, compresi
sistema operativo, ruolo del dominio, livello di sicurezza e normali ore di
gestione, applicando poi le regole di categorizzazione a tali informazioni.
Gli amministratori possono adeguare le regole di elaborazione di GFI LANguard
S.E.L.M. alle esigenze e caratteristiche specifiche della rete.
Categorizzazione basata sul luogo di raccolta dell'evento
Gli accessi di rete alle stazioni di lavoro devono essere considerati come sospetti, in quanto gli aggressori che ottengono l'accesso remoto ad una stazione di lavoro possono fingere di essere l'utente di quella stazione di lavoro ed utilizzarne le credenziali per accedere ad altri server della rete. Di conseguenza, GFI LANguard S.E.L.M. classifica gli accessi di rete a stazioni di lavoro come più gravi di quelli effettuati a controllori di dominio o server.
Controllo delle stazioni di lavoro e dei server su tutta la rete
Le regole di categorizzazione predefinite di GFI LANguard S.E.L.M. riconoscono
scenari specifici, compresi:
o accessi non riusciti
o blocchi di account
o creazioni di account fuori orario e variazioni delle appartenenze ai gruppi
o accessi fuori orario a sistemi ad elevata sicurezza
o ingresso in stazioni di lavoro degli utenti tramite accessi di rete
o modifiche alla politica di controllo
o log della sicurezza cancellati
o accessi riusciti o non riusciti a file (compreso l'accesso a file specifici).
È possibile classificare un evento in vari modi, a seconda delle circostanze.
Per questo, quando GFI LANguard S.E.L.M. categorizza un evento, include una
descrizione che spiega in modo specifico il motivo di tale categorizzazione.
La descrizione spiega inoltre cosa l'evento potrebbe indicare e suggerisce ulteriori
azioni che l'amministratore può intraprendere per confermare e far fronte
alla situazione.
Per impostazione predefinita, GFI LANguard S.E.L.M. notifica gli eventi critici
inviando email SMTP, ma gli amministratori possono scegliere di ricevere tali
notifiche per eventi dal livello di sicurezza minore.
L'amministratore deve considerare il livello di sicurezza relativa del suo computer,
il potenziale carico di prestazioni rispetto alle necessarie tempistiche dei
messaggi di allerta e i gli scenari di rischio specifici del suo ambiente.
5.4 Analisi della dovuta diligenza
Per soddisfare le richieste di verifica di controlli generali da parte di revisori pubblici e autorità di vigilanza, le aziende devono integrare il controllo in tempo reale con un riesame regolare degli eventi di gravità minore. Per aiutare gli amministratori a seguire tale raccomandazione senza doversi essi stessi dedicare a tempo pieno a tale compito, GFI LANguard S.E.L.M. comprende numerosi rapporti pre-costituiti. Gli amministratori possono seguire gli eventi di ogni gravità semplicemente rivedendo i rapporti sugli eventi della sicurezza elevati del giorno prima, quelli a media sicurezza della settimana precedente e quelli a bassa sicurezza del mese precedente, con cadenza rispettivamente giornaliera, settimanale o mensile. Rapporti supplementari permettono agli amministratori di rivedere l'attività del giorno corrente o gli eventi a media e bassa sicurezza con una frequenza maggiore.
5.5 Selezionare gli idonei livelli di sicurezza per i computer
GFI LANguard S.E.L.M. si affida all'amministratore per selezionare il livello di sicurezza idoneo di ogni computer controllato. Quando registra una stazione di lavoro, l'amministratore deve tener conto dell'utente assegnato a tale stazione. Le stazioni di lavoro di utenti che hanno accesso a risorse importanti, quali gli amministratori, e degli utenti che effettuano transazioni finanziarie, dovrebbero essere configurate come a rischio di sicurezza elevato. Ulteriori stazioni di lavoro che possono essere classificate come a sicurezza elevata sono quelle localizzate nella sala computer e quelli che ospitano procedure critiche, come il sistema di accesso fisico nell'azienda. Le stazioni di lavoro di utenti che hanno scarso accesso ad informazioni o procedure critiche dovrebbero essere configurate come a basso rischio di sicurezza. La classificazione nel medio rischio di sicurezza può essere utilizzata per le stazioni di lavoro di utenti che rientrano fra questi due estremi.
5.6 Equilibrare il consumo di risorse con avvisi
tempestivi
La frequenza con la quale GFI LANguard S.E.L.M raccoglie gli eventi da ciascun computer controllato si ripercuote sull'utilizzo della CPU dei computer e sulla complessiva larghezza di banda della rete. Maggiore è il livello di sicurezza di un computer, maggiore sarà la frequenza di interrogazione del computer stesso, benché la frequenza di raccolta sia influenzata anche dal ruolo del computer. Per esempio, una stazione di lavoro dal livello di sicurezza elevato è di solito meno importante di un server con lo stesso livello.
5.7 Garantire manutenzione ed integrità dei log della
sicurezza
Tecnicamente, un attacco ben organizzato su di un sistema non opportunamente configurato può consentire ad un intruso di ottenere l'autorità di Amministratore sul computer e cancellare il log prima della successiva raccolta operata da GFI LANguard S.E.L.M. Tuttavia, Windows registra fedelmente uno specifico evento ogniqualvolta il log viene cancellato, persino quando il controllo è stato disabilitato e, per impostazione predefinita, GFI LANguard S.E.L.M. classifica quell'evento come critico su ogni sistema.
Pertanto, si adotti la politica di non cancellare mai un log della sicurezza manualmente su computer controllati da GFI LANguard S.E.L.M. (una tale politica è comunque la prassi migliore da adottare, in quanto assicura che gli eventi non vengano mai persi e preserva la responsabilità tra amministratori). Per impostazione predefinita, GFI LANguard S.E.L.M. cancella automaticamente il log della sicurezza ogni volta che il programma raccoglie gli eventi, perciò la cancellazione manuale del log non è mai necessaria.
Windows richiede una dimensione massima del log per ogni computer. Quando il log raggiunge il limite preimpostato,il sistema operativo interrompe la registrazione delle attività. Così, se il log si riempie nel corso delle raccolte di GFI LANguard S.E.L.M., delle attività importanti potrebbero andare perdute. Gli amministratori devono configurare la dimensione massima del log della sicurezza di ciascun sistema, in base alla frequenza di raccolta di GFI LANguard S.E.L.M. e al volume di attività di quel computer. Per sistemi dall'elevata frequenza di raccolta da parte di GFI LANguard S.E.L.M., persino un log spropositatamente di piccole dimensioni non avrebbe l'opportunità di riempirsi. D'altronde, considerate le dimensioni dei dischi attualmente disponibili, è inutile impostare un log di piccole dimensioni. Gli amministratori possono eliminare qualsiasi incertezza semplicemente utilizzando un log degli eventi standard di Windows delle dimensioni comprese tra 5 e 10MB.
Windows può essere configurato in modo da bloccarsi quando il log della sicurezza si riempie. Tale impostazione può risultare necessaria per computer dal livello di rischio della sicurezza molto critico o ai fini dell'osservanza di requisiti di verifica contabile (ad esempio, su sistemi che controllano bonifici elettronici). Tuttavia, per minimizzare la possibilità di tali blocchi, gli amministratori devono impostare intervalli di raccolta di GFI LANguard S.E.L.M. brevi ed una dimensione del log sufficiente a garantire che il computer non possa elaborare un'attività tale da riempire il log durante detti intervalli.
5.8 Utilizzo del controllo di accesso ai file per la sicurezza interna
Il controllo dei file di Windows consente agli amministratori di abilitare
il controllo su file selezionati per determinati tipi di accesso. Si rivela
il più utile per controllare le modalità di accesso a documenti
come file Microsoft Excel e Microsoft Word da parte degli utenti. Questo tipo
di controllo può inoltre essere utilizzato per monitorare eventi quali
variazioni di cartelle contenenti eseguibili o tentativi non autorizzati di
accesso ai file di database.
Com'è prevedibile, GFI LANguard S.E.L.M. contiene regole di categorizzazione
per tutti gli eventi di oggetti, ma offre anche la capacità di promuovere
eventi di accesso all'oggetto connessi a file o directory importanti (secondo
quanto specificato dall'amministratore). Tale capacità consente all'amministratore
di abilitare il controllo per tutti i file o directory che desidera, ma, allo
stesso tempo, di configurare GFI LANguard S.E.L.M. affinché sia particolarmente
attento a file e cartelle cruciali. L'amministratore si limita a configurare
il controllo di tutti gli oggetti desiderati e, poi, imposta GFI LANguard S.E.L.M.
perché promuova allo stato di evento critico tutti gli eventi collegati
a determinati nomi di file o cartelle.
Quando configura il controllo dell'oggetto, l'amministratore deve prendere in
considerazione tre vettori:
o quali oggetti controllare
o quali soggetti (ossia, utenti o gruppi) rintracciare per ciascun oggetto
o quali tipi di accesso controllare per ciascun soggetto.
Maggiore è il numero di oggetti controllati, maggiore sarà il
consumo di tampo della CPU, larghezza di banda della rete e spazio sul disco.
5.9 Rilevare l'intrusione e il defacement del
server web
Per i server web, il controllo dei log della sicurezza in tempo reale è estremamente importante ed efficace, in quanto l'identificazione di attività sospetta sui server web è più semplice di quella eseguita sui server della rete interna. Il controllo di accesso ai file è particolarmente prezioso nell'individuazione di defacement. Un server web configurato secondo la migliore prassi conterrà cartelle di file HTML, ASP e d'immagini chiaramente definite. Questi file sono moderatamente statici rispetto ai database o ad altri file che vengono modificati in risposta ai soggetti che navigano sul sito. Configurando Windows perché controlli eventuali modifiche riuscite a tali directory e GFI LANguard S.E.L.M. affinché promuova gli eventi di accesso collegati ai nomi dei file presenti in dette directory, l'amministratore verrà informato immediatamente di qualsiasi modifica al sito Web. Per prevenire i falsi positivi prodotti dagli aggiornamenti legittimi al sito Web, si renderà necessario disabilitare temporaneamente il controllo di eventi di accesso all'oggetto riusciti. Così facendo si impedisce a Windows di registrare gli aggiornamenti. Se l'amministratore desidera semplicemente impedire l'invio di messaggi di allerta, un metodo alternativo consiste nell'eliminare il nome della relativa cartella dall'elenco di "osservati speciali" di GFI LANguard S.E.L.M. Le modifiche vengono sempre registrate da Windows e classificate nel database di GFI LANguard S.E.L.M. secondo le regole di categorizzazione del prodotto, ma gli eventi non sono più promossi come di livello critico, perciò non viene inviato alcun messaggio di allerta.
Windows contiene una funzionalità di "cattura" degli eventi
della sicurezza completa, ma offre poco o nulla in materia di analisi, archiviazione
e capacità di controllo in tempo reale. Descrizioni sibilline degli eventi
complicano ulteriormente il problema, così come il fatto che ciascun
computer mantiene un log della sicurezza distinto. Eppure, in un ambiente aziendale
collegato in rete come quello odierno, è essenziale rintracciare le attività
di sicurezza e rispondere immediatamente ai tentativi d'intrusione. GFI LANguard
S.E.L.M. si aggiunge ai controlli di base di Windows per offrire un modo semplice
da impiegare, per soddisfare tali esigenze. E un'installazione di GFI LANguard
S.E.L.M. ben impiegata si traduce in una riduzione dei falsi positivi delle
procedure di allerta, nella responsabilità degli amministratori e in
log di archivio sicuri.
Classifica l'evento come:
critico
alto
medio
basso
Crea dei report personalizzati
Utilizza tecnologia Microsoft Windows
Usa regole di categorizzazione per classificare gli eventi
Notifica via mail
Frequenza di raccolta eventi personalizzata
Promuove eventi di accesso all'oggetto connessi a file o directory importanti.
SecurityReport è il servizio proposto da Nexa per la raccolta e l'analisi
delle Statistiche, dei Report e degli Attacchi relativi alla Sicurezza aziendale.
Modulo opzionale attivabile sui sistemi di Security basati su tecnologia FTG
implementati da Nexa, consente di aggregare ed analizzare in maniera semplice
e sicura le informazioni dei Log provenienti da sistemi multipli Antivirus/Firewall
realizzati con apparecchi firewall; il tutto per fornire all'amministratore
di rete una visione completa dell'utilizzo della rete ed importanti informazioni
sulla sicurezza dei sistemi.
L'obiettivo principale è rendere molto più semplice l'identificazione
e la relativa soluzione di vulnerabilità eventualmente disperse su installazioni
di apparati multipli.
Vengono così ridotte le risorse necessarie alla manutenzione delle politiche
di sicurezza e all'identificazione degli attacchi rilevati dai dispositivi firewall,
inclusi traffico, eventi di sistema, virus, attacchi ed accessi ai contenuti
sul Web e via e-mail (HTTP, FTP, IMAP, POP3 and SMTP).
Questa specifica soluzione per l'archiviazione e l'analisi dei Log rappresenta
il completamento ideale dell'intera architettura di sicurezza per le aziende
MSSP (Managed Security Services Provider) per offrire un servizio di sicurezza
gestita di assoluto livello a costi estremamente contenuti.
Il servizio SecurityReport, erogato dalla sede Nexa, è consultabile tramite
una interfaccia grafica intuitiva, completa di grafici statistici e report chiari
e concisi.
Il sistema è inoltre in grado di raccogliere ed elaborare i log a scadenze
prefissate, al fine di estrarre e generare i report scelti dal Cliente in HTML,
PDF o MS Word. Il file estratto può essere inviato direttamente ed automaticamente
al Cliente via eMail o potrà essere collocato su una specifica area Extranet
del portale Nexa, per le analisi ed i controlli successivi.
I record dei Log sono trasmessi dai firewall al sistema SecurityReport attraverso
tunnel VPN criptati con la sede Nexa, per garantire la massima sicurezza e riservatezza
dei dati.
In sintesi, il sistema SecurityReport fornisce un punto centrale per l'analisi
dell'utilizzo della rete, dell'attività Web e dell'attività di
attacco attraverso sistemi multipli di firewall, aumentando la sicurezza e l'affidabilità
della rete e dei dati.
6.2 Caratteristiche dei report
Sono disponibili ben 11 categorie di Report con più di 140 report, la cui generazione è flessibile e completamente configurabile.
I parametri dei Report definibili sono:
" il periodo
" le query
" i filtri
" periodo di schedulazione delle elaborazioni
" i formati dei dati in uscita
Le notifiche delle analisi dei Report possono essere configurate:
" per singolo dispositivo
" per tutti i dispositivi (qualora fossero presenti più apparati
o più sedi dotate di firewall)
6.3 Caratteristiche di gestione dei log
Il sistema permette una Gestione dei Log completa di:
" Esportazione ed importazione dei Log per una corretta storicizzazione
e visualizzazione degli stessi
" Analisi degli eventi divisi per le seguenti tipologie:
o Eventi
o Traffico
o Attacchi
o Antivirus
o Web Filter
o E-mail Filter
o Meta Content
" Notifica tramite E-mail per gli Eventi reimpostati, tipicamente per
gli attacchi critici.
" Integrazione con le regole di privacy HIPAA e con altre regole definite
dai Clienti
6.4 Correlazione attacchi ed eventi
Il sistema fornisce un veloce reperimento, grazie ad una grafica user-friendly,
delle seguenti informazioni relative agli attacchi:
" localizzazione degli attacchi provenienti dalla stessa fonte/sorgente
" localizzazione di tutti i target (obiettivi) dello stesso attacco
Il risultato concreto è un incremento nell'efficacia di gestione della
rete grazie alla possibilità di isolare gli attacchi ed identificare
rapidamente le modalità di risoluzione dei problemi.

Monitorare il funzionamento delle applicazioni è un'attività
tanto più critica quanto più l'applicazione gestisce processi
"core" per l'azienda. Ancora più importante è analizzare
il comportamento degli utilizzatori dell'applicazione soprattutto se si tratta
di applicazioni web che sono a disposizione dei clienti.
L'analisi comportamentale fornisce una abbondante serie di indicatori per poter
effettuare scelte particolarmente strategiche. Naturalmente, oltre ai clienti,
sono estremamente significativi i comportamenti di fornitori, partner, dipendenti,
cittadini.
Lo strumento tipico di monitoraggio del comportamento delle applicazioni è
la gestione di log prodotti dalle applicazioni durante il loro funzionamento.
La gestione dei log delle applicazioni consiste principalmente in due attività,
la creazione dei dati di log e la loro elaborazione per produrre tracciati dati
utilizzabili da altre componenti applicative.
La fase di elaborazione dei dati dei log riveste un ruolo fondamentale. Il risultato
delle elaborazioni deve essere memorizzato in strutture dati accessibili in
modo assolutamente trasparente.
ACP Profiler è la tecnologia sviluppata nei laboratori ACP per il monitoraggio,
la memorizzazione e la gestione di tutti gli venti che si verificano all'interno
di un'applicazione (diretta o indiretta conseguenza delle interazioni utente-applicazione).
ACP Profiler è una libreria configurabile mediante file XML, facilmente
estendibile ed integrabile in ogni applicazione realizzata in linguaggio Java.
ACP Profiler può trattare gli eventi che si verificano all'interno delle
applicazioni non come semplici righe di un file di log ma come oggetti strutturati
secondo il file XML definito con una struttura in grado di portare informazioni.
ACP Profiler è stato infatti realizzato per non essere legato ad uno
specifico campo applicativo o ad una specifica applicazioni, ma per adattarsi
al modello degli eventi che diverse applicazioni sono in grado di generare.
In ACP Profiler gli ebventi sono organizzati in canali/ambienti diversi. Ad
ogni canale/ambiente può corrispondere una comunità, un servizio,
un contenuto, una comunicazione, o qualsiasi altro elemento logico dell'applicazione.
I canali sono organizzati in modo gerarchico, come pure la gestione delle loro
attivazione e disattivazione (attivando e disattivando un canale ad un livello
gerarchico specifico è possibile propagare la stessa azione a tutti i
sottolivelli).
ACP Profiler è progettato su un'architettura scalabile che separa il
repository degli eventi dall'applicazione. È quindi possibile avere la
stessa applicazione su più macchine in bilanciamento di carico o distribuita
su più macchine con compiti diversi, ma avere un unico punto di rilevazione
degli eventi con un unico repository centralizzato.
ACP Profiler si affida ad un indice destrutturato per memorizzare gli eventi,
i metadati e le informazioni.
ACP Profiler è stato concepito per non essere legato a nessun tipo di
file system. In caso di transazioni concorrenti, l'integrità e l'atomicità
della rilevazione degli eventi viene garantita attraverso un sistema di lock
management distribuito, basato sul protocollo http.
ACP Profiler riceve dall'applicazione la rilevazione dell'evento e le informazioni
allegate, attraverso una chiamata alle API messe a disposizione dalla libreria
Java.
Tali informazioni vengono poi arricchite con dati aggiuntivi di sintesi e vengono
conservate, per un tempo configurabile, in una memoria di caching. Ad intervalli
fissati, vengono poi inserite all'interno dell'indice destrutturato e diventano
persistenti.
Ogni attributo legato ad un evento può divenire, a livello di indice,
una chiave di aggregazione e di ricerca per analisi statistiche e rilevazioni
di modelli di comportamento.
ACP Profiler è in grado di elaborare ed archiviare anche eventi prodotti
da applicazioni e tecnologie esterne alla suite ACP.
Le API della tecnologia possono essere utilizzate da applicazioni non ACP per
la generazione di eventi.
Implementando un plugin per una specifica API di accesso , ACP Profiler può
essere configurato per leggere direttamente da file di log con struttura eterogenea,
prodotti da qualsiasi applicazione.
ACP Profiler permette di effettuare una prima analisi dei dati raccolti, in
quanto mette a disposizione alcune primitive per la gestione dei dati.
Utilizzando le API è possibile:
" Filtrare l'analisi su eventi/oggetti di tipo specifico, mediante l'impostazione
di vincoli sulle proprietà degli eventi
" Aggregare gli eventi secondo criteri multipli e specifici della struttura
del tracciato di log (ad esempio nel caso di tracciati che registrano l'accesso
alle pagine di un'applicazione WEB è possibile raggruppare l'analisi
per utenti o per tipo di pagine)
" Generare semplici indicatori statistici sui dati raccolti (conteggio
delle occorrenze in periodi di tempo configurabili, somma dei dati aggregati
o ordinamento dei dati)
" Rilevare eventi anomali secondo criteri definiti dall'utente
" Generare output tabellari in XML (su schema definito dall'utente), testo
piano, file MS EXCEL, HTML.
Realizzata completamente con tecnologia Java ed XML (SDK java 1.4.1)
Interfaccia di programmazione del server basata su API Java.
Rappresentazione dei log con template XML personalizzati.
Gestione di canali/ambienti gerarchici.
Gestione di tracciati log personalizzati
Generazione di indicatori statistici
Rilevazione di eventi secondo criteri definiti dall'utente.
Generazione di output tabellari.
news ed articoli sul problema della sicurezza
Artiolo: "MSS: gestione e sicurezza vanno a braccetto" di Lorenzo Grillo
da web magazine online
corsi e servizi LINUX
Guide e manuali per webmaster:
Guida ad apache
www.risorse.net/apache/analisi_log.asp
Le informazioni riguardanti i tre applicativi sono state reperite dai siti delle rispettive aziende: