Buffer overflow
Moltissime persone sanno cosa è un exploit, ma chi si affaccia per la prima volta al mondo della sicurezza informatica potrebbe non sapere nemmeno di cosa si tratti e per questo iniziamo a porre le basi spiegando prima di tutto cos’è un exploit.
Un exploit non è nient’altro che un programma scritto tipicamente in C (ma anche in altri linguaggi) che permette di sfruttare delle falle (le cosiddette vulnerabilità) di altri programmi per poter eseguire sul sistema del codice dannoso che in condizioni "normali" non dovrebbe essere possibile eseguire.
Tale programma exploit, ossia acquisisce illegalmente il controllo di una caratteristica di un programma vulnerabile o del sistema operativo per scopi propri.
Gli
attacchi di tipo buffer overflow rappresentano la stragrande maggioranza di
tutti gli attacchi ai sistemi informatici in quanto le vulnerabilità del buffer
overflow sono comuni e quindi relativamente facili da sfruttare. Le
vulnerabilità del buffer overflow sono la principale causa di intrusioni in
sistemi informatici anche perché esse offrono all’attaccante la possibilità di
eseguire codice dannoso.
Il
codice introdotto viene eseguito dal sistema con i privilegi del programma
bucato e permette all’attaccante di poter controllare altri servizi dell’host
vittima che gli interessa controllare.
Ma che cosa si intende per buffer? Il buffer è un blocco contiguo di memoria che risiede nella memoria del PC e che immagazzina dati relativi all’applicazione. In C un buffer viene chiamato array, questi ultimi possono essere dichiarati statici o dinamici: le variabili statiche sono allocate al momento del caricamento sul segmento dati, quelle dinamiche sono allocate al momento del caricamento sullo stack di sistema. L’overflow, come si può intuire dal termine stesso, consiste nel riempire un buffer oltre il limite. Per la realizzazione di un exploit di buffer overflow vengono sfruttati gli array dinamici.
Per comprendere il funzionamento dei buffer sullo stack e come alcuni errori di programmazione possano essere usati per generare buffer overflow, bisogna prima capire il sistema con cui il computer gestisce la memoria di un processo.
Memory layout di un processo
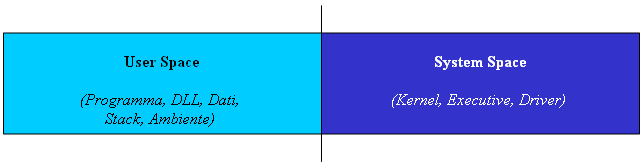
Lo spazio di indirizzamento di un processo è diviso fondamentalmente in due regioni principali:
- il system space (kernel)
- l’user space (programma e DLL)
All’interno di quest’ultima regione la memoria a disposizione del processo può essere ulteriormente divisa nelle seguenti sezioni:
-
codice
-
stack
-
dati
(inizializzati e non inizializzati)
Graficamente, il memory layout di un processo appare come segue:
Focalizzeremo, ora, la nostra attenzione sull’user space di un generico processo.
User Space
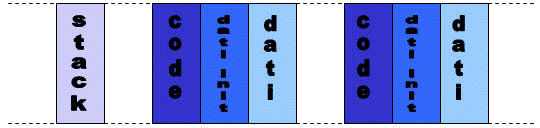
Come detto in precedenza, questa regione dello spazio di memoria di un processo può essere ulteriormente divisa in altre sezioni, ciascuna con dei permessi di accesso:
- codice: contiene il codice del programma in modalità di sola lettura; per questo motivo un eventuale tentativo di scrittura provoca una violazione di segmento.
- stack: usato per allocare dinamicamente le variabili locali usate nelle funzioni, per passare parametri alle funzioni e per restituire valori dalle stesse. I permessi di accesso sono lettura, scrittura ed esecuzione.
- dati: in questa sezione vengono immagazzinate le variabili statiche e la sua dimensione può essere modificata con la chiamata di sistema brk(). Per i dati inizializzati i permessi sono di lettura ed esecuzione, per quelli non inizializzati, invece, i permessi sono di lettura, scrittura ed esecuzione.
Si mostra di seguito un esempio di user space di un processo:
prova.exe NTDLL.DLL
Ai fini di una migliore comprensione, vale la pena dare qualche ulteriore informazione circa l’uso e il funzionamento dello stack durante l’esecuzione di processo.
Cos’è lo stack
La prima domanda cui bisogna dare una risposta è la seguente: cosa è uno stack?
Per definizione, uno stack è un tipo di dato astratto. Uno stack di oggetti ha la proprietà Last In First Out (LIFO), cioè l’ultimo oggetto inserito è il primo ad essere rimosso. Le due operazioni principali sono push e pop: push aggiunge un elemento in cima allo stack e pop lo rimuove.
Passiamo ora a considerare in che modo viene usato lo stack durante l’esecuzione di un generico processo.
I linguaggi di programmazione moderni hanno il costrutto di procedura o funzione. Una chiamata a procedura altera il flusso di controllo come un salto (jump), ma, diversamente da un salto, una volta finito il proprio compito, una funzione ritorna il controllo all’istruzione successiva alla chiamata. Questa astrazione può essere implementata con il supporto di una struttura dati come lo stack.
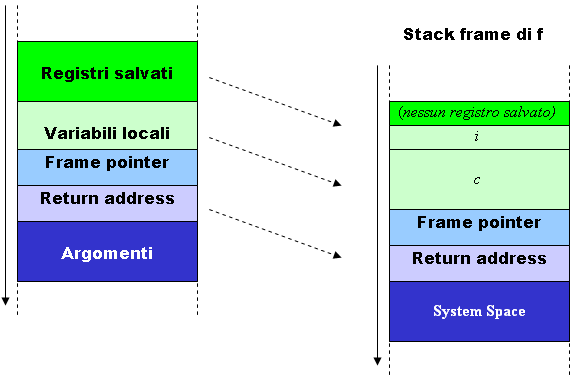
Uno stack è un blocco di memoria contiguo contenente dei dati. Un registro noto come stack pointer (SP) punta alla cima dello stack, conosciuta più propriamente con il termine di top dello stack: è su questo top (e solo su di esso) che vengono fatte le operazioni di push e pop .
La base dello stack è un indirizzo fisso. La dimensione è variata dinamicamente dal kernel. La CPU implementa le operazioni push e pop.
Lo stack consiste di un insieme di segmenti logici (stack frame) che vengono impilati (pushed) sullo stack quando viene chiamata una funzione e spilati (popped) quando la funzione ritorna. Uno stack frame contiene i parametri della funzione, le sue variabili locali, i dati necessari per ripristinare il precedente stack frame, incluso l’indirizzo dell’istruzione successiva alla chiamata (contenuto nell’instruction pointer o IP). A seconda dell’implementazione, lo stack, cresce verso l’alto o il basso.
Oltre allo stack pointer si ha anche un frame pointer (FP) che punta ad una locazione fissa nel frame, noto anche come base pointer (BP). Le variabili locali possono essere referenziate specificando l’offset dallo stack pointer. Tuttavia, poiché nuovi dati sono impilati e spilati, tale offset cambia. Quindi si usa referenziare le variabili locali e i parametri con un offset da FP.
Stack frame di una funzione C
Mostriamo, ora, cosa succede allo spazio di memoria di un processo in presenza di una chiamata ad una funzione come quella che è definita di seguito:

Cosa succede quando viene invocata tale funzione?
Innanzitutto diamo le seguenti definizioni necessarie alla comprensione di quanto verrà detto in seguito:
- BP o FP o frame pointer: è il valore salvato del registro usato per indirizzare le variabili locali; esso punta ad una locazione fissa all’interno di uno stack frame
- SP o stack pointer: è il puntatore allo stack, o più precisamente al top dello stack; l’indirizzo di base dello stack è invece un indirizzo fisso
- IP o instruction pointer: contiene l’indirizzo dell’istruzione successiva alla chiamata
In seguito ad una chiamata alla funzione f vengono eseguite le seguenti operazioni:
- push fp: viene salvato sullo stack il frame pointer (FP) precedente per poterlo poi ripristinare al ritorno dalla funzione
- mov fp, sp :si copia SP su FP per creare il nuovo FP
- si incrementa SP per puntare allo spazio riservato per la successiva variabile locale.
Graficamente lo stack frame di una funzione appare come segue:
Le conoscenze fornite fino a questo punto dovrebbero essere sufficienti e comprendere come delle vulnerabilità di buffer overflow possano essere sfruttate tramite attacchi ed exploit costruiti ad hoc per ottenere il controllo del programma “da bucare”.
Il motivo di fondo di un attacco di buffer overflow, come detto in precedenza, è di prendere il controllo del programma eseguito e, nel caso che il software abbia sufficienti privilegi, di prendere finanche il controllo dell’host stesso. E’, infatti, consuetudine che l’attaccante scelga un applicativo che "gira" come root per poter avere direttamente una shell di root sul sistema attaccato, questo è anche uno dei motivi per cui software come, ad esempio, sendmail (che gira con i privilegi di root) sono stati tra i più utilizzati per attacchi di buffer overflow. Fortunamente questo non è sempre possibile in quanto per poter ottenere una shell di root chi attacca il sistema deve preparare il codice da utilizzare e da far eseguire nello spazio d’indirizzamento del programma, permettere all’applicativo di saltare a quella porzione di codice con parametri esatti, caricati nei registri e nella memoria.