Gli sniffer sono nati in risposta alla necessità di avere uno strumento che esegue il debug delle comunicazioni in rete. Essi catturano i pacchetti che viaggiano sulla rete senza però alterarli, li interpretano ed eventualmente li memorizzano per un’analisi successiva. In questo modo gli amministratori di rete sono in grado di individuare e risolvere i problemi di comunicazione, consultando il traffico nella sua forma “primordiale”.
Come la maggior parte dei potenti strumenti di amministrazione delle reti, anche gli sniffer sono stati trasformati, nel corso degli anni, per poter “aiutare” gli hacker più smaliziati. Si può facilmente immaginare la quantità di preziose informazioni che passano attraverso un segmento di rete anche in un breve intervallo: è possibile intercettare coppie di nome utente e password, messaggi di posta elettronica confidenziali, interi file con informazioni finanziarie, industriali, grafici di vendita e così via. Perciò qualunque cosa è trasmessa in rete è una possibile preda di uno sniffer in ascolto.
Le funzioni tipiche degli sniffer non differiscono di molto e possono essere riassunte sinteticamente in:
Gli sniffer rappresentano un rischio elevato per una rete o per il pc dell’utente. La semplice esistenza di uno sniffer in rete rappresenta una falla e una minaccia alla sicurezza e alla riservatezza delle comunicazioni all’interno della rete stessa.
Se la rete che si utilizza è sottoposta al “controllo” di uno sniffer, ci sono due possibilità: un intruso, dall’esterno è riuscito ad entrare nella rete e ad installare lo sniffer, oppure un utente o il gestore della rete stessa sta andando ben oltre la manutenzione e il monitoraggio delle connessioni.
In ogni caso la privacy, o peggio ancora, la sicurezza stessa di tutte le comunicazioni, è compromessa.
Sebbene uno sniffer possa essere installato ovunque nella rete, esistono dei punti strategici che permettendo la raccolta di determinate informazioni. Uno di questi è un qualsiasi punto adiacente ad una macchina in cui si presume passino notevoli quantità di password; ad esempio un gateway di rete oppure un nodo che smisti il traffico in entrata e in uscita della rete stessa.
Se la LAN è connessa con l'esterno, si può presumere che lo sniffer cercherà di monitorare le procedure d’autenticazione con le altre reti, cosa che permetterebbe di aumentare in via esponenziale le possibilità invasive di chi lo gestisce.
Lo sniffer generalmente è installato, sia esso hardware o software, all’interno dello stesso segmento della rete che si vuole controllare.
Ovviamente esistono numerose eccezioni che rendono spesso difficile individuare i punti esatti in cui cercare uno sniffer all’interno della rete. Questo è ancor più vero per alcuni tool, sviluppati per operare analisi di traffico al livello dello stesso cavo di rete (cable sniffer); possono essere impiantati direttamente sulla connessione fisica della rete.
Ecco l’architettura di cattura di un generico sniffer:
Le informazioni che viaggiano attraverso una rete Ethernet, sono ricevute contemporaneamente da tutte le schede connesse al bus interessato dal traffico dei pacchetti di dati. Nell'header Ethernet di ciascun pacchetto è specificato l'indirizzo (MAC address) dell'interfaccia del destinatario. Le interfacce controllano se questo indirizzo di destinazione corrisponde al proprio e in tal caso passano l'informazione agli strati superiori, altrimenti la ignorano.
Le schede di rete, tuttavia, supportano la cosiddetta modalità promiscua, che consente loro di accettare tutto il traffico in viaggio sulla rete, indipendentemente dall'indirizzo di destinazione, e conseguentemente di passarlo ad una applicazione in grado di analizzarlo.
Predisponendo una scheda di rete in modalità promiscua e realizzando opportuni filtri, è possibile monitorare tutto o parte del traffico che passa attraverso il tratto di rete al quale è connessa la propria postazione.
Questo è il principio sul quale si basano gli analizzatori di rete, strumenti utili per scoprire e risolvere eventuali anomalie.
Molte versioni di Unix forniscono una interfaccia a livello di collegamento, mediante un driver basato sul kernel, detto BPF (Berkeley Packet Filter), che possiede alcune ottime funzioni che agevolano enormemente l'elaborazione e il filtraggio dei pacchetti.
Il driver BPF possiede, infatti, un meccanismo di filtraggio nel kernel, realizzato mediante una macchina virtuale. Questa macchina è dotata di semplicissime istruzioni, che consentono l'esame di ciascun pacchetto attraverso un piccolo programma che l'utente carica nel kernel. Il programma viene eseguito sul pacchetto appena ricevuto e quest'ultimo viene passato agli strati più alti dell'applicazione solo se corrisponde alle specifiche del filtro.
Il driver BPF è costituito da due componenti: il network tap e il packet filter.
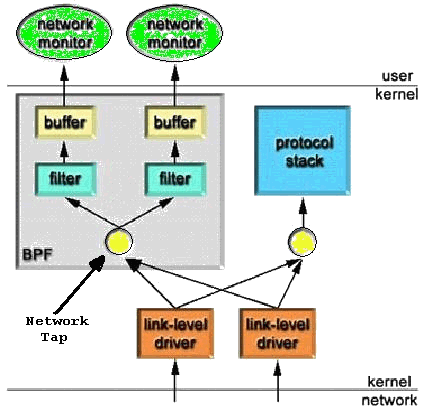
Il network tap non fa altro che collezionare copie dei pacchetti provenienti dal device driver di rete e smistarle alle applicazioni che sono in ascolto. Dopo ciò è il filtro a decidere se la copia del pacchetto verrà accettata. Quando un pacchetto arriva all'interfaccia di rete, normalmente il device driver lo passa allo stack di protocollo. Quando il BPF è attivo, su tale interfaccia, il driver chiama per prima cosa il BPF. Quest'ultimo passa il pacchetto ad ogni filtro a livello utente in ascolto, che si occupa poi di decidere se o quale parte del pacchetto passare all'applicazione.
Quindi per ogni filtro che accetta il pacchetto, il BPF crea una copia del quantitativo richiesto di dati nel buffer associato con quel filtro.
Dopo ciò, il device driver riprende il controllo e consegna il pacchetto allo stack di protocollo se era ivi destinato, altrimenti lo lascia transitare.
Poiché i programmi di monitoraggio della rete, spesso, richiedono di esaminare soltanto una parte dei pacchetti, il packet filtering svolge un grosso lavoro di filtraggio. Per minimizzare il carico in memoria, che costituisce il principale collo di bottiglia nelle workstation, il pacchetto viene filtrato là dove il DMA dell'interfaccia di rete lo memorizza senza copiarlo in un altro buffer del kernel. In questo modo, se il pacchetto viene scartato, soltanto i pochi byte richiesti dal processo del filtro vengono referenziati. E' per questo che il BPF è preferibile agli altri, quali ad esempio lo STREAMS NIT della SUN che copia sempre il pacchetto in un buffer prima di passarlo al filtro che dovrà esaminarlo ed in seguito accettarlo o rifiutarlo. In questo modo il NIT spreca cicli di CPU anche per i pacchetti che non corrispondono alle specifiche del filtro. Un Packet Filter non è altro che una funzione booleana sul pacchetto. Se la funzione restituisce true il kernel copia il pacchetto all'applicazione, se restituisce false il pacchetto viene ignorato. Il BPF utilizza un grafo diretto aciclico di controllo flusso per effettuare il controllo sul flusso di pacchetti.

Nel modello a grafo i nodi rappresentano un campo predicato sul pacchetto e gli archi i trasferimenti di controllo. Il vantaggio della rappresentazione con grafo è che esso ricorda l'analisi (parsing) fatta in precedenza, poiché può ogni volta essere riorganizzato, in modo tale che il valore (true o false) venga direttamente utilizzato ai nodi.
Questo tipo di espressione descrive in maniera sintetica il tipo di traffico che lo sniffer dovrà elaborare, solo quei pacchetti per cui l'espressione filtro è vera saranno catturati. L'espressione filtro è una sequenza di ASCII che consiste di uno o più primitive. Le primitive consistono di solito di un id (nome o numero) preceduto da uno o più qualificatori. Ci sono tre tipi di qualificatori:
Per accedere ai dati nel pacchetto si usa la sintassi seguente:
proto è una delle parole chiavi ip, arp, rarp, tcp o icmp, ed indica lo strato di protocollo per l'operazione di indice. Il byte di offset relativo allo strato di protocollo indicato è dato da expr. L' indicatore size è opzionale ed indica il numero di byte nel campo di interesse; può essere uno, due, o quattro, e di default è un byte. L'operatore di lunghezza, indicato dalla parola chiave len dà la lunghezza del pacchetto.
Libpcap è una libreria portatile multipiattaforma che implementa il sistema di filtraggio BPF.
Il progetto ha inizio nel giugno del 1994 per opera di Van Jacobson, Craig Leres e Steven McCanne, al Lawrence Berkeley National Laboratory, University of California, Berkeley, CA. Attualmente il progetto è gestito dal "The Tcpdump Group".
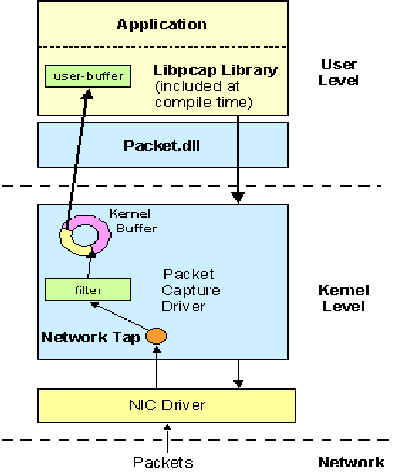
Libpcap astrae l'interfaccia del livello collegamento del protocollo TCP su svariati sistemi operativi e crea un'API semplice e standardizzata. Ciò consente la creazione di codice portabile in grado di utilizzare una sola interfaccia per più sistemi operativi.
Attualmente libpcap è disponibile per quasi tutti i sistemi operativi Unix ed esiste un porting anche in ambiente Windows denominato winpcap.
La libreria che noi utilizzeremo è un wrapper di tale libreria, la Jpcap, che ci ha permesso di realizzare un applicazione per il monitoraggio della rete sfruttando le enormi potenzialità e vantaggi dell’ambiente java e della libreria libpcap.