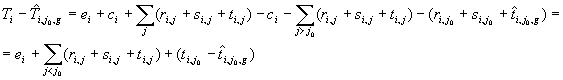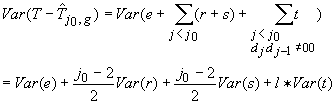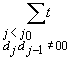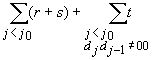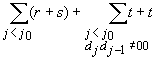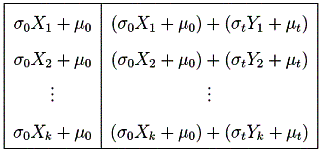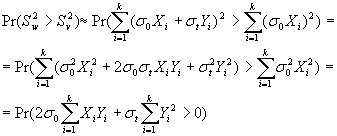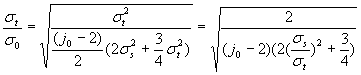Timing Attack ad RSA

![]()
![]()
![]()
|
Timing Attack ad RSA
|
|
|
Sia
j0
un particolare valore di j
nell’algoritmo left-to-rigth di
figura 3, e sia
dove
Allora
si può verificare che il valore
Se
non è corretto, allora
La
sottrazione del termine
La variabile casuale r ed s descrive quanto tempo serve per eseguire il quadrato di un elemento di Assumendo
che il tempo per il calcolo del quadrato e della moltiplicazione nei cicli
successivi sono indipendenti da ognuno e dall’errore, la varianza della
variabile casuale
La
variabile l è un intero che è determinato dal
numero di coppie di bit prese da d
che non sono uguali a 00 (per un
valore casuale di d, l è approssimativamente uguale a
Così,
r ed s sono identicamente distribuite e la
varianza di
Quando
il valore di g
ipotizzato è scorretto, allora ci
sono due possibilità per la varianza di
Innanzitutto,
supponiamo che entrambi ti,j0 e
Poi,
supponiamo che una tra ti,j0 o
In
questo modo, la colonna dei dati basata su una corretta ipotesi ha una varianza
che è Var(t) oppure 2*Var(t) più bassa delle altre colonne di
dati. La varianza campione, S2, è una buona stima della varianza effettiva e noi potremmo presentare una
stima euristica della probabilità che questa statistica distinguerà la
corretta colonna. Per
sviluppare la nostra stima, prima introduciamo alcune note e consideriamo due
argomenti che sono stati stabiliti in molti testi introduttivi della probabilità
[10
]. Scriviamo
La
colonna dei dati nella tabella di Oscar, che corrisponde ad una corretta
ipotesi, ha una varianza attesa di Var(e)+(j0-2)Var(s)+l*Var(t). C’è una seconda colonna nella tabella di Oscar che ha una varianza attesa
di Var(e)+(j0-2)Var(s)+(l+1)*Var(t) . Queste due varianze differiscono per il valore di
Var(t). Supponiamo che esiste una terza colonna di dati con varianza attesa
Var(e)+(j0-2)Var(s)+(l+2)*Var(t). In questo caso la varianza differisce dalla prima colonna per un valore di
2*Var(t). La
probabilità di successo del test statistico di Oscar, che consiste nel
calcolare S2, è più basso quando egli la calcola alla prima e seconda colonna, opposto a
quando la applica alla prima e terza colonna. Quindi, noi deriviamo una stima di
questa probabilità di successo nel caso peggiore. Una stima della probabilità
in altri casi, può essere ricavata in modo simile. Supponiamo
che r,s,t siano normalmente distribuite.
Denotiamo con
sono
normalmente distribuite e i dati nelle colonne corrette e incorrette della
tabella sono distribuite in accordo alle seguenti somme:
Entrambe
le somme di queste variabili casuali sono normalmente distribuite. Denotiamo la
distribuzione del primo con
Supponiamo
che abbiamo un totale di k
misure di tempo accurate. Siano X1,X2,...,Xk e
Y1,Y2,...,Yk le variazioni normali standard
corrette ed errate rispettivamente. Se gli effetti di errore sono
insignificanti, possiamo modellare i dati in due colonne come:
Per
semplificare la nostra notazione, poniamo
Le
variabili Vi e Wi sono normalmente distribuite con le
media di µ0
e µ0+t rispettivamente. Così, se k è grande, allora
Ora,
consideriamo alcune nozioni del calcolo delle probabilità. L’identità Var(X)=E(X2)-E(X)2
visualizza che E(Xi2)=1 e E(Yi2)=1, poiché
Xi
e Yi
sono normalmente distribuite. A
questo punto,
Ancora,
Var(Xi,Yi)=E(Xi2Yi2)-(E(XiYi))2=E(Xi2Yi2)=E(Xi2)E(Yi2)=1. Applicando il teorema del limite centrale, allora
dove
Notiamo
che, come ci aspettavamo, la probabilità è più grande del primo caso. Ricordiamo
che
Questa
è la probabilità di successo, e in ognuno dei due casi, dipende dai valori di
|
|
|