|
|
|
|
|
Il WWW č forse l'applicazione piů frequentemente usata su Internet, quindi l' importanza dell' anonimia
nel web browsing č certamente in crescita siccome sempre piů web server tengono traccia di
utenti mentre questi navigano di sito in sito.Il corrente stato della tecnologia World Wide Web fornisce
ampie opportunitŕ ai siti Web di collezionare informazioni personali su di un utente. Una delle piů ovvie
minacce alla privacy dell' utente proviene dalle informazioni liberamente passate da esso stesso. Infatti
l' utente le fornisce ingenuamente rispondendo a delle indagini, acquistando con carte di credito,
inoltrando e-mail... . Altre minacce alla privacy, meno visibili, di cui gli utenti non sono spesso a conoscenza, sono incorporate nell'architettura stessa di Internet e del World Wide Web. Inoltre, gli utenti posseggono poco controllo sul flusso di queste informazioni. Una possibile soluzione di base alla mancanza di anonimia in Internet č l'utilizzo di un particolare server proxy. Un server proxy agisce sostanzialmente come un buffer tra computer e risorse Internet (Sito Web, Archivio FTP). In genere, i server proxy sono utilizzati per velocizzare le operazioni in Internet, poiché essi memorizzano in una cache le pagine richieste piů spesso.  Questa figura illustra il modo di operare di un normale server proxy. Essi inoltrano le richieste per conto degli utenti fornendo il loro indirizzo IP. Anonymizer [1] e molti altri sistemi simili sono costituiti essenzialmente da un server proxy che agisce come tramite tra gli utenti e il sito che desiderano visitare. Gli utenti, invece di connettersi direttamente al server Web, si connettono ad Anonymizer e chiedono ad esso di recuperare una determinata pagina Web. Anonymizer perň, a differenza di un normale server proxy, (vedere Figura) fornisce un insieme di accorgimenti, tra i quali quello di eliminare tutte le informazioni di identificazione dell' utente e di filtrare i cookie, allo scopo di tutelare la privacy dell'utente. Esso rende cosě il web browsing privato in assenza di "origliamento" o analisi del traffico sulla rete.  Anonymizer č un sistema che fornisce un buon livello di "data anonimity" e un basso livello di "connection anonymity". La Figura illustra come viaggiano i dati dall' utente al sito da lui richiesto. In assenza del server anonymizer la richiesta sarebbe stata inoltrata direttamente dal browser al sito. E' chiaro che il sito non č in grado di collegare una richiesta ad un utente siccome quest' ultima gli č stata inoltrata da anonymizer (l'indirizzo IP viene occultato, gli http header modificati e i cookie filtrati) e non direttamente da un utente. Anonymizer opera in maniera simile ai remailer di tipo 0, con la sostanziale differenza che, in generale, č piů affidabile. Ricordiamo, che i remailer di tipo 0 mantengono una tabella permanente di associazioni fra indirizzi e-mail reali e indirizzi e-mail fittizi, per garantire le reply. Anonymizer, se fidato, non ha motivo di registrare i dati dell'utente permanentemente (indirizzo IP) e non ha modo di associare l' identitŕ dell' utente alle sue richieste successive (non usufruisce dei cookie). E' preferibile in ogni caso, per una maggiore anonimia, che gli indirizzi IP siano dinamici. Anonymizer, come i remailer di tipo 0, č vulnerabile all'attacco di un nemico esterno che č in grado di osservare le richieste entranti e quelle uscenti dal proxy e di correlarle (analisi del traffico). Anonymizer č il piů popolare dei servizi di privacy online ed č in funzione dal 1996. Il suo server č collocato a San Diego ed attualmente carica un milione di pagine al giorno sia per conto dei suoi iscritti sia per altri utenti. Il presidente del servizio č Lance Cottrel l'ideatore dei Mixmaster Remailer. Abbiamo giŕ accennato, in precedenza, all'esistenza di siti Web che utilizzano i cookie per identificare i loro utenti e fornire pagine personalizzate. Altri siti Web, invece offrono servizi personalizzati (personalized Web browsing) richiedendo agli utenti di fornire una username, una password segreta e l'indirizzo e-mail. Fornire il proprio reale indirizzo e-mail puň dare la possibilitŕ a questi siti di costruire un database di utenti basato proprio sugli indirizzi e-mail. Questo database puň essere facilmente usato per inviare junk-email (spam). Molti utenti, per evitare di essere soggetti allo spamming, preferiscono non utilizzare tali servizi e preservare la loro anonimia. Altri invece li utilizzano registrandosi con dati fasulli. Il problema fondamentale di questa soluzione č che l'utente deve inventare e ricordare una username distinta, una password sicura ed un indirizzo e-mail per ogni sito Web. Questo per evitare che i siti, collaborando, possano collegare tali alias alla vera identitŕ dell'utente, stilando cosě un vero e proprio profilo utente. Fare una tale operazione per ogni sito puň essere enormemente pesante e tedioso. Inoltre, molti siti inviano un codice di conferma all'indirizzo e-mail dell'utente in maniera tale che l'utente che desidera accedere al servizio deve fornire tale codice. Il Lucent Personalized Web Assistant, o LPWA [6], sviluppato dai Bell Laboratories, fornisce un servizio di anonimia personalizzato per il web browsing. Molti siti web richiedono all' utente di fornire una username ed una password. Questo permette al sito web di offrire un servizio personalizzato. Sfortunatamente la maggior parte degli utenti sceglie una username facile da ricordare e che puň essere facilmente collegata alla propria reale identitŕ. LPWA č costituito da un server proxy, che provvede alla rimozione degli header http e al filtraggio dei cookie, insieme ad un sistema che fornisce una privacy agli utenti attraverso una differente, anonima e non collegabile username/password, per ogni sito web diverso, mentre l' utente deve solo ricordarne una segreta. Questa operazione č realizzata con la funzione hash pseudo-casuale chiamata Janus. Essa trasforma un' identitŕ id, un sito web w e un valore S segreto, in una username u ed una password p per il sito web w : Le proprietŕ che la funzione Janus deve garantire sono: - Anonimia degli utenti: un sito Web o piů siti non devono essere in grado di determinare l'identitŕ di un utente; - Consistenza: per ogni sito Web un utente ha un unico alias e deve essere riconosciuto ad ogni visita; - Efficientemente computabile: deve essere velocemente calcolabile; - Segretezza della password: un alias username non deve dare informazioni su ogni altra alias password; - Unicitŕ degli alias tra gli utenti: nessun utente deve avere lo stesso alias con lo stesso sito Web; - Protezione dalla creazione di un dossier: un alias di un utente relativo ad un certo sito Web non deve rivelare nessuna informazioni circa un alias dello stesso utente relativo ad un altro sito Web. Ciň comporta che anche se piů siti collaborano al fine di una creazione di un dossier, essi non devono riuscire a mettere in relazione i vari alias degli utenti; - Accettabilitŕ: gli alias generati dalla funzione J devono essere accettati dai diversi siti Web, cioč devono avere un appropriato range ed una giusta lunghezza. Prima del browsing del WWW, l' utente deve collegarsi al LPWA dando la propria identitŕ in segreto. Dopo tale operazione, LPWA č usato come un web proxy intermedio. Qualora un sito web chieda la username e la password, l' utente scrive '\U' e '\P', che vendono rimpiazzati da LPWA con i valori u e p. Gli autori, come risultato di alcune considerazioni sulle componenti principali del sistema, hanno deciso di effettuare un collaudo pubblico di LPWA. La configurazione risultante č illustrata nella seguente figura :  LPWA fornisce un servizio di e-mail anonimo nello stesso modo. Come Anonymizer, LPWA fornisce anonimia dati ed un basso livello di connessione anonima. Comunque, Janus potrebbe essere usato in combinazione con qualsiasi altra soluzione di comunicazione anonima, aggiungendo ad esso un web browsing personalizzato. LPWA in uso L'utente configura il proprio browser, settandolo per l'uso del proxy LPWA, in modo tale che ogni richiesta ad un sito Web ed ogni risposta č instradata attraverso LPWA. Quindi, all'inizio di ogni sessione, all'utente č presentata la pagina login di LPWA. Questa pagina chiede all' utente di fornire la sua user ID (la sua e-mail reale) ed il segreto (password universale). Qualora un sito Web richieda all'utente di fornire la username, la sua password e l'indirizzo e-mail, l'utente chiama il personal generator, che si occupa della generazione delle identitŕ, e digita i seguenti caratteri: - \U per richiedere l'alias per l'username; - \P per richiedere l'alias per la password; - \@ per richiedere l'alias per l'indirizzo e-mail. LPWA riconosce queste sequenze, computa un alias username, una password e l'indirizzo e-mail per il sito Web specifico e li inserisce nella request dell' utente. Il servizio LPWA sta ora venendo commmercializzato come ProxiMate [14]. Crowds [16] č un sistema per il browsing anonimo sviluppato nel 1997 da Michael Reiter ed Aviel Rubin presso i laboratori AT&T. Nella soluzione Crowd, gli utenti si uniscono in gruppo (crowd), e le richieste vengono soddisfatte collettivamente. L' assegnazione di un utente ad una certo crowd avviene attraverso un protocollo di ammissione tra un programma chiamato jondo, residente sulla macchina dell'utente, e un server denominato blender. L' utente inizia la connessione facendo partire il jondo, il quale si collega al server blender. Il server blender verifica che l' utente č autorizzato all' uso del sistema attraverso una password ed una username. Se l' utente č autorizzato, blender fornisce al jondo le informazioni relative al crowd di cui farŕ parte: lo informa sugli altri elementi del crowd e gli fornisce una chiave simmetrica per ognuno dei membri del crowd. Ovviamente anche la comunicazione tra il blender e i jondo č cifrata. Inoltre il blender informa i membri del crowd del nuovo membro e fornisce ad ognuno di loro la chiave simmetrica per comunicare con esso. Una volta che l' utente entra a far parte di un crowd, nel momento in cui richiede una URL attraverso il suo browser, la richiesta č inoltrata al jondo piuttosto che al server che corrisponde a quell'URL. Dopo aver ricevuto tale richiesta, il jondo toglie tutte le informazioni di identificazione, sottomette le richieste al server destinazione, oppure avanza le richieste ad un altro jondo. Questo percorso di jondi č inizializzato da una scelta casuale, ma rimane lo stesso per l' intera sessione. Le richieste e le repliche seguono la stessa path ma la comunicazione tra jondi č cifrata. Una path di jondi viene alterata soltanto nel momento in cui si verifica una disconnessione di un jondo, oppure quando si aggiunge un nuovo jondo. In questo ultimo caso, tutti le path dei precedenti jondi vengono "dimenticate" e nuove path vengono stabilite, cosicché la path iniziata dal nuovo jondo non č individuabile dagli altri jondi. Come ogni jondo non puň rivelare se una richiesta č iniziata da un jondo precedente, o da uno prima di esso, cosě anche gli utenti mantengono il proprio anonimato all' interno di un gruppo. Un sistema Crowd (gruppo) č essenzialmente un Anonymizer distribuito ed "incatenato", con link cifrati tra due membri del Crowd, fornendo sia dati anonimi che una connessione ad alto livello di anonimia. La figura seguente illustra un esempio di possibili path in un crowd, osserviamo che utenti e server da loro richiesti sono etichettati con lo stesso numero. 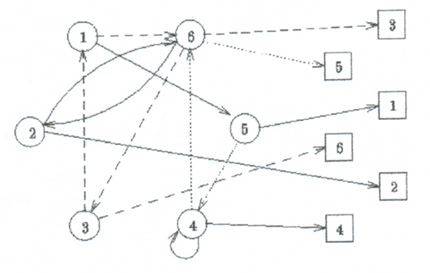 Crowd, a differenza degli altri sistemi di anonimia esaminati finora, non si avvale dell'utilizzo di un server proxy per fornire la sender anonymity. I sistemi basati sull'uso di un unico server proxy che si interpone tra mittente e ricevente, come Anonymizer e LPWA, sono sistemi che garantiscono la sender anonymity rispetto al server Web ma sono inefficaci contro altri tipi di nemici. Osserviamo, infatti, che i sistemi basati su un unico server proxy sono interamente vulnerabili ad un nemico esterno locale che puň controllare i messaggi entranti e uscenti dal proxy e correlarli (analisi del traffico). Le crowd sono meno esposte a questo tipo di attacco. Questo č dovuto principalmente al fatto che il server blender č utilizzato solo per formare le crowd e non prende parte al successivo sistema di inoltramento delle richieste. Il limite di questa soluzione č perň che il server web puň registrare l'indirizzo IP del jondo finale ritenendo che esso sia il reale richiedente, anche se un web server (ed altre persone, se le informazioni di logging sono rese pubbliche) non puň vedere la differenza tra un jondo di un utente finale, che fa le richieste per un utente anonimo di un gruppo, ed un utente finale che effettua le proprie richieste direttamente. In ogni caso le crowd sono efficaci sia nel garantire la sender anonymity dell' utente rispetto all' end server (partner di comunicazione) sia rispetto ad un elemento della crowd stessa (nemico interno al sistema). Inoltre offrono una certa protezione rispetto a nemici esterni locali passivi. Crowd č un sistema che fornisce un buon livello di "data anonymity" e alcune proprietŕ della "connection anonymity". Osserviamo che con crowd, per quanto concerne la data anonymity, č affidato ai jondi il compito per default di filtrare i cookie anche se č data la possibilitŕ all' utente di configurare il jondo in modo tale da accettarli. Inoltre č sempre lasciato alla volontŕ dell' utente la possibilitŕ di stabilire quali header devono essere forniti insieme alla richiesta e quali tipi di componenti (Java e JavaScript) č permesso far passare al browser. E' inoltre fortemente consigliato all' utente di disabilitare i Java Applet e Active X dal proprio browser. Per quanto concerne la connection anonymity osserviamo che crowd offre infatti una certa protezione dagli attaccanti interni e da un certo tipo di attaccanti esterni (attaccante esterno locale passivo o local eavesdropper ). Crowds č un sistema prevalentemente software disponibile solo negli Stati Uniti e in Canada. Il software crowd non č a pagamento. Le precedenti soluzioni sono rivolte tutte al browsing anonimo del WWW. In molti casi č desiderata la pubblicitŕ anonima sul WWW. I Rewebbers e i server TAZ [7] forniscono una soluzione a questa esigenza. L'idea di base č di collocare lungo la rete un insieme di nodi chiamati rewebber. I rewebber sono server proxy in grado di gestire URL nidificati cioč nella forma (molti http proxy presentano questo comportamento). L' idea fondamentale č di pubblicare un URL nidificato in maniera tale che esso punti ad un rewebber anziché ad un sito reale. Per nascondere il sito reale, ovviamente, č utilizzato un meccanismo di cifratura : l'URL reale viene cifrato con una chiave pubblica assegnata al rewebber in maniera tale che solo esso č in grado di ricavarlo. Ovviamente per ulteriore sicurezza č meglio utilizzare piů rewebber (chaining). Questi URL nidificati e cifrati, che vengono denominati locator, hanno la stessa struttura di cifratura dei remailer di tipo 1-2 : 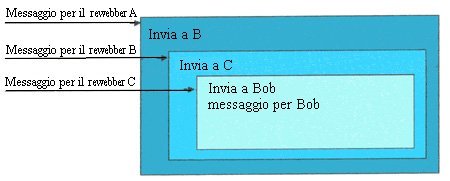 Analizziamo l'esempio in Figura. Abbiamo tre rewebber A, B, e C. Il sito reale viene cifrato con la chiave pubblica di C ed il tutto č cifrato, rispettivamente, con la chiave pubblica di B e poi di A. Il rewebber A, utilizzando la sua chiave privata, elimina lo strato superiore di cifratura e ricava l' indirizzo del prossimo rewebber a cui puntare, ovvero B; a sua volta il rewebber B ricava che deve puntare al rewebber C ed infine C punta al sito reale. Questo meccanismo nasconde la reale posizione del server al client, ma presenta alcuni problemi. Prima di tutto, una volta che il client ha recuperato i dati dal rewebber, potrebbe usare un motore di ricerca piů potente per tentare scoprire da dove il documento proviene originariamente. Per risolvere questo problema, il documento viene cifrato con una chiave simmetrica prima di essere memorizzato nel server. Pertanto, se il documento viene acceduto direttamente, si presenterŕ sottoforma di dati casuali. La chiave simmetrica č fornita al rewebber nella parte cifrata del locator. Quindi, quando il rewebber decifra la sua parte del locator, non trova solo l'URL da recuperare, ma anche una chiave simmetrica per cifrare il documento. Questa tecnica di cifrare il documento ha anche un altro beneficio: al documento puň essere applicato il padding prima di cifrarlo, ed il rewebber puň eliminare i bit casuali prima di fornire il documento al client. Questo č utile affinché il client non effettui una ricerca tramite la lunghezza del documento. Janus č stato sviluppato tra il 1997 e il 1998 al "Department of Communication Systems" presso l'Universitŕ Fern di Hagen in Germania. Rewebber Janus Janus č un sistema sia per il browsing anonimo (simile ad Anonymazer) sia per il publishing anonimo (rewebber). Janus non si serve dei taz server. In particolare gli URL cifrati da Janus sono costituiti da tre parti essenziali: - L'indirizzo del Janus server utilizzato nel processo di cifratura; - Un comando Janus; - L'URL cifrato. |