L’era genomica ha assistito ad una crescita esponenziale delle informazioni biologiche rese disponibili dai progressi nel campo della biologia
molecolare. In particolare, il sequenziamento del genoma umano e di altri organismi ha dato un forte impulso a quel settore della bioinformatica che
si occupa dello studio del DNA e delle proteine. La grande sfida che la comunità scientifica sta ora affrontando consiste nel cercare di analizzare e
capire l’enorme quantità di dati prodotta in laboratorio.
La bioinformatica e’ la disciplina che si occupa dello sviluppo e dell'integrazione delle applicazioni della scienza dell’informazione al servizio della
ricerca scientifica in campo biotecnologico. Per fare ciò utilizza strumenti informatici per analizzare i dati biologici che descrivono sequenze di geni,
composizione e struttura delle proteine, processi biochimici nelle cellule, etc. La bioinformatica si occupa fra l'altro di organizzare le conoscenze
acquisite a livello globale su genoma e proteoma in basi di dati al fine di rendere tali dati accessibili a tutti, e ottimizzare gli algoritmi di ricerca
dei dati stessi per migliorarne l'accessibilità.
Una delle attività principali dei bioinformatici consiste nella progettazione, costruzione e uso di banche dati di interesse biologico.
Una banca dati raccoglie dati e informazioni derivati da esperimenti di laboratorio, da esperimenti in silico (cioe’ utilizzare il dato informatico
come punto di partenza per gli esperimenti in vitro. Si dice "in silico", in quanto i processori dei calcolatori sono costituiti da silicio) e dalla
letteratura scientifica. Una banca dati è costituita da voci (in inglese entry) ciascuna contenente informazioni sull’oggetto caratteristico della
banca dati: sequenze nucleotidiche ( per sequenza intendiamo una stringa di caratteri ognuno dei quali rappresenta un nucleotide ), referenze bibliografiche insieme a tutte le altre informazioni che si riferiscono alla entry in particolare.
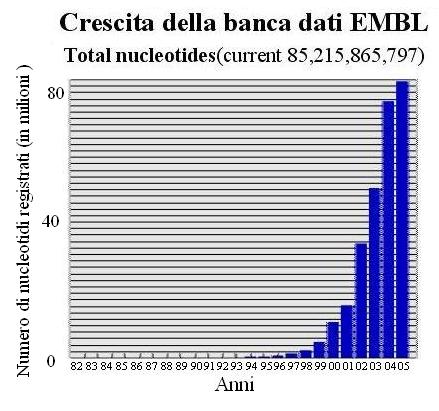
A testimonianza della sempre maggior rilevanza della bioinformatica riportiamo, nella figura seguente, la crescita dal 1982 al 2005 della banca dati EMBL.
Quest'ultimo è l'istituto di biologia molecolare europea, ed è un'organizzazione di ricerca internazionale che ha laboratori in molti paesi del mondo.
Lo scopo della EMBL è di rendere facili le ricerche basate sulla biologia molecolare e sullo sviluppo tecnologico.
Una volta che i dati sono stati archiviati nelle banche dati biologiche è necessario utilizzare alcuni strumenti bioinformatici in modo tale da
ricavarne informazioni. Essi si sono sviluppati in accordo ai seguenti tre processi biologici fondamentali:
- la sequenza del DNA determina la sequenza aminoacidica della proteina (mediante il processo della sintesi proteica);
- la sequenza aminoacidica determina la struttura tridimensionale della proteina;
- la struttura tridimensionale della proteina ne determina la funzione.
La bioinformatica ha focalizzato la sua analisi su dati relativi a tali processi, e di conseguenza le banche dati costituiscono un potente supporto
per una vasta gamma di ricerche quali, ad esempio:
- data una sequenza di acidi nucleici o proteica trovare una sequenza simile in banca dati;
- data una struttura proteica trovare, in banca dati, una struttura simile ad essa;
- data una sequenza proteica prevedere una possibile struttura tridimensionale.
Questo tipo di ricerche data l'enorme mole di informazioni archiviate risulta proibitiva se non addirittura impossibile senza l'utilizzo di strumenti informatici. A questo proposito furono sviluppati nel 1990 da Stephen Altschul[1], Warren Gish, David Lipman in America presso l'NCBI (Centro nazionale per la ricerca biotecnologica), da Webb Miller presso l'università di stato della Pensilvenia, e da Gene Myers presso l'università dell'Arizona l'algoritmo BLAST (acronimo di Basic Local Alignment Search Tool ) e il programma che lo implementa. BLAST è utilizzato per identificare le similarità (cioè la "somiglianza") fra le nuove sequenze con funzione e struttura sconosciuta e le sequenze (archiviate nelle banche dati) la cui struttura e funzione sono note, rendendo così possibile individuare la funzione delle prime. Blast quindi si propore come strumento utile per effettuare rapide ricerche di nucleotidi e di proteine all'interno di database.