3. Meccanismi e Architetture Firewall
Un firewall è un insieme di componenti logiche e fisiche il
cui scopo principale è separare una rete privata da Internet e stabilire a
quali servizi interni si possa accedere dall’esterno e a quali servizi esterni si
possa accedere dall’interno. La separazione si ottiene facendo in modo che la
comunicazione con il mondo esterno avvenga solo attraverso la mediazione di una
o poche macchine della rete privata che costituiscono il firewall. Il firewall
fa da tramite per le richieste di servizio provenienti dalla rete interna verso
Internet e viceversa. Le macchine che non comunicano direttamente con l’esterno
costituiscono la rete interna. La migliore separazione si ottiene collocando
quanto più possibile sul firewall i servizi da offrire al mondo esterno.
Tuttavia ciò non è possibile quando si è vincolati a offrire
all’esterno servizi, come ad esempio telnet, che intrinsecamente richiedono
l’accesso a macchine appartenenti alla rete interna. In questo caso il firewall
si limita a fare da tramite e a selezionare le richieste di accesso esterno ed
eventualmente a fornire meccanismi di autenticazione. Le macchine collegate
direttamente con Internet, cioè quelle che forniscono servizi all’esterno e
fanno da tramite con la rete interna, sono quelle sulle quali è necessario
concentrare maggiori attenzioni nella gestione della sicurezza e vengono
denominate bastion host. Nel seguito, nelle
architetture firewall descritte, si farà riferimento per brevità ad un unico
bastion host anche se è sempre possibile pensare ad un numero variabile di
macchine di questo tipo.
Questa descrizione generale non deve essere considerata
rigidamente, sono infatti possibili variazioni che dipendono dai requisiti di
sicurezza e dai vincoli dettati dalle esigenze di disponibilità dei servizi.
Tali vincoli possono riflettersi nella necessità di offrire collegamenti
diretti anche con macchine appartenenti alla rete interna anche se questo
comporta una minore separazione dal mondo esterno e conseguentemente maggiori
vulnerabilità per la rete privata.
Quanto più è netta la separazione tra rete interna e mondo
esterno realizzata dal firewall, tanto più è possibile concentrare la gestione
della sicurezza sulle macchine che costituiscono il firewall stesso. Una
rigorosa separazione, infatti, consente di preoccuparsi meno dei problemi di
sicurezza delle macchine appartenenti alla rete interna realizzando così
l’obbiettivo della centralizzazione della gestione della sicurezza di una rete
privata su poche macchine affacciate su Internet.
I meccanismi che possono essere utilizzati da un firewall
sono:
Packet filtering,
una tecnica usata per bloccare il transito di certe classi di traffico, in base
agli indirizzi e ai servizi richiesti;
Proxy service,
programmi che fanno da tramite inoltrando richieste di servizio tra rete
interna e Internet ed eventualmente filtrano queste richieste basandosi sulle
informazioni degli specifici protocolli applicativi;
Logging, meccanismi di
registrazione degli accessi, utilizzati da una grande varietà di sistemi che
assumono particolare rilevanza nel caso di un firewall, in quanto questo
costituisce il punto di transito per tutto il traffico della rete;
Autenticazione di utente,
meccanismo di tipo crittografico che permette di verificare l’identità degli
utenti.
Complessivamente, un firewall può proteggere i servizi
offerti dalla rete privata, può controllare e gestire gli accessi a questa, può
impedire la diffusione di informazioni relative alla configurazione della rete
privata e può valutare e misurare il traffico.
Un firewall può essere realizzato con un router, un personal
computer, una workstation, o mediante una opportuna combinazione di alcuni di
questi, facendo uso dei meccanismi appena descritti. Le diverse architetture di
un firewall sono il risultato di tale combinazione e della configurazione degli
elementi utilizzati.
Nei prossimi paragrafi vengono descritti più in dettaglio i
meccanismi e gli elementi utilizzati per realizzare un firewall, e alcune
architetture di riferimento.
Come in tutti i protocolli di rete, lo schema di
indirizzamento IP è parte integrante del processo di instradamento (routing)
dei pacchetti IP attraverso la rete. Un indirizzo IP è lungo 32 bit, ed è
suddiviso in due o tre parti: la prima parte individua l’indirizzo di rete, la
seconda parte, se presente, individua l’indirizzo di sottorete, la terza parte
individua l’indirizzo dell’host.
L’indirizzo di sottorete è presente solo se è stato definito
dall’amministratore di rete, e ha validità solo all’interno della rete stessa.
La lunghezza di questi tre campi è variabile: l’indirizzo di rete è fornito dai
bit più a sinistra dell’indirizzo; il numero di bit utilizzati per individuare
la rete dipende dalla classe a cui appartiene l’indirizzo. Le classi di
indirizzo IP sono:
classe A, per la quale i primi 8 bit individuano
l’indirizzo di rete e il primo di questi assume valore 0; fornisce quindi 7 bit
per lo spazio degli indirizzi di rete e 24 bit per lo spazio degli indirizzi di
host;
classe B, per la quale i primi 16 bit individuano l’indirizzo
di rete e i primi due assumono valore 1 e 0; fornisce quindi 14 bit per lo
spazio degli indirizzi di rete e 16 bit per lo spazio degli indirizzi di host;
classe C, per la quale i primi 24 bit individuano l’indirizzo
di rete e i primi tre assumono valore 1, 1 e 0; fornisce quindi 21 bit per lo
spazio degli indirizzi di rete e 8 bit per lo spazio degli indirizzi di host.
I router, i dispositivi deputati all’instradamento, sono
organizzati gerarchicamente. Alcuni di essi vengono utilizzati per trasferire
informazioni attraverso un particolare gruppo di reti gestite e controllate
dalla stessa autorità amministrativa. Tali gruppi vengono chiamati sistemi autonomi.
I router utilizzati per lo scambio di informazioni
all’interno di sistemi autonomi vengono chiamati router interni (interior
routers) e, a questo scopo, possono impiegare diversi protocolli anch’essi
detti interni (IGP, Interiors
Gateway Protocols).
Analogamente i router che trasferiscono informazioni tra
sistemi autonomi vengono chiamati router esterni (exterior routers) e, a questo
scopo, possono impiegare diversi protocolli detti esterni (EGP, Exteriors Gateway Protocols).
I protocolli di routing IP sono dinamici in quanto, a intervalli regolari di
tempo, richiedono al software dei dispositivi di routing di calcolare i
percorsi e conseguentemente permettono di aggiornare le tabelle di routing che
consistono di coppie “indirizzo destinazione” / “passo successivo”. Il routing
IP prevede che i pacchetti IP viaggino sulla rete un passo alla volta. L’intero
percorso non è conosciuto all’inizio del viaggio: a ogni passo la destinazione
successiva viene calcolata cercando una corrispondenza
tra l’indirizzo del pacchetto e una riga della tabella di
routing del nodo corrente. Il coinvolgimento di ogni nodo nel processo di
routing consiste unicamente nell’instradamento di pacchetti in base a
informazioni interne senza che ciascun nodo si preoccupi del fatto che il
pacchetto possa o meno raggiungere la destinazione finale.
Tutte le macchine sono coinvolte in decisioni di routing.
Per la maggior parte degli host queste decisioni sono semplici: se l’host
destinazione si trova sulla rete locale, i dati sono trasmessi direttamente a
questo; se l’host destinazione si trova su una rete remota, i dati sono
inoltrati ad un router locale. Nel primo caso l’indirizzo fisico e l’indirizzo
di rete individuano la stessa macchina, nel secondo caso il pacchetto contiene
l’indirizzo fisico del router locale e l’indirizzo di rete della macchina
remota destinazione.
Per ogni pacchetto in transito il router, esaminando l’indirizzo
destinazione, determina se è in grado o meno di inoltrare il pacchetto stesso
verso la destinazione successiva (next hop). Nel primo caso invia il pacchetto
al router successivo cambiando l’indirizzo fisico destinazione, nel secondo
scarta il pacchetto. [3]
Il packet filtering (filtraggio di pacchetti) è un meccanismo di sicurezza che agisce controllando e selezionando i dati che transitano da e verso una rete. La selezione del traffico permesso o proibito viene effettuata in base all’esame dei pacchetti in transito sul sistema che effettua il filtraggio. Normalmente la possibilità di filtrare pacchetti è fornita direttamente dal
software dei router i quali, dopo avere stabilito dove
instradare i pacchetti consultando la tabella di routing, verificano che ne sia
permesso l’instradamento. Questo tipo di decisioni viene preso in base alle
cosiddette regole di packet filtering. Un router di questo tipo viene detto
screening router.
Il packet filtering permette di controllare il trasferimento
dei dati in base a:
l’indirizzo da cui provengono i dati (di cui non è
garantita l’autenticità);
l’indirizzo a cui sono destinati i dati;
l’identificativo di protocollo di trasporto utilizzato per
trasferire i dati;
l’identificativo di protocollo applicativo (il numero di
porta logica);
alcune informazioni di controllo (ad esempio il bit di
acknowledgement).
A seconda della flessibilità del router il filtraggio dei pacchetti può essere effettuato sull’interfaccia di ingresso, su quella di uscita o su entrambe. Le decisioni non dipendono dal contenuto applicativo dei pacchetti, ma esclusivamente dall’esame delle intestazioni dei singoli pacchetti. E’ quindi possibile, ad esempio, programmare un router in maniera tale da permettere sessioni telnet da una data macchina verso un sistema remoto, ma non è possibile programmarlo in maniera tale da definire quali utenti siano autorizzati ad effettuare il collegamento. Sono possibili due tipi di filtraggio: address filtering e service filtering. Nel primo caso le uniche informazioni che vengono prese in esame sono gli indirizzi sorgente e destinazione del pacchetto, nel secondo caso vengono analizzati anche il tipo di protocollo di trasporto, i numeri di porta logica nell’intestazione dello strato di trasporto (e quindi implicitamente il servizio richiesto) e il bit di acknowledgement ACK.
La configurazione di uno screening router è composta di tre
passi:
1. stabilire una politica di controllo degli accessi;
2. specificare in termini logici il tipo di pacchetti
permessi o negati;
3. scrivere la lista delle regole con la sintassi del
sistema che si sta utilizzando.
Per descrivere un caso concreto, supponiamo che una data
rete scelga di configurare il proprio router che si affaccia su Internet in
maniera da permette esclusivamente connessioni di tipo telnet dall’interno
verso l’esterno e nient’altro. Una tabella logica che descrive un filtro con
queste caratteristiche è la seguente (Figura 4):
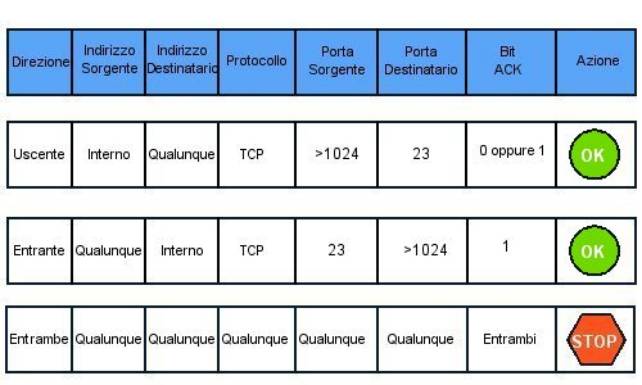
Figura 4: Configurazione di un router mediante tabella logica
Nella sintassi dei router Cisco, una tabella logica di questo tipo si traduce nella definizione di uno o più elenchi di regole di accesso, chiamate ACL (Access Control List), da associare alle interfacce del router. In questo esempio si definiranno due ACL distinte da associare rispettivamente all’interfaccia esterna (serial 0) per selezionare il traffico uscente e a quella interna (ethernet 0) per selezionare il traffico entrante. Una ACL è composta di righe che descrivono le regole di accesso. Ciascuna riga descrive nell’ordine: l’identificativo della ACL, l’azione da eseguire, il tipo di protocollo da selezionare, una coppia (indirizzo, maschera) che descrive la sorgente, una coppia analoga per la destinazione, la porta o l’intervallo di porte destinazione ed eventualmente l’opzione ESTABLISHED che verifica che il bit ACK sia posto a 1. Se ad esempio la rete in questione ha indirizzo 192.201.127.0, la tabella logica precedente si traduce nelle due seguenti ACL (Figura 5):

Figura 5: Access Control List di un Router Cisco
In generale, e quindi anche nel caso dei router Cisco, per
ogni pacchetto in transito il router prova ad applicare alle informazioni del
pacchetto le regole relative all’interfaccia attraverso cui deve essere
instradato, esaminandole dall’alto verso il basso. Non appena trova una regola
applicabile al pacchetto esegue l’azione indicata e interrompe l’esame delle
regole. Nel caso non vi siano regole applicabili a un pacchetto, il router
esegue un’azione prestabilita, normalmente scartare il pacchetto.
In analogia al filtraggio in base al numero di porta
effettuato su pacchetti TCP e UDP,
alcuni router permettono il filtraggio di pacchetti ICMP in base all’identificativo di messaggio contenuto.
Un’altra importante possibilità offerta da alcuni screening
router (come ad esempio i Cisco) è quella di analizzare i bit di opzione
nell’intestazione IP per verificare se i pacchetti in esame presentino
l’opzione di source routing, ed eventualmente scartarli.
L’uso del packet filtering come meccanismo di
protezione presenta due grandi vantaggi: le misure che possono essere definite sono
completamente trasparenti per gli utenti; le stesse macchine indispensabili al
collegamento ad Internet, i router, possiedono di per sé tali meccanismi.
Inoltre vi sono alcune forme di protezione che possono essere fornite solo da
uno screening router. Ad esempio un router può facilmente essere programmato
per riconoscere situazioni in cui si sta cercando di introdurre dall’esterno
pacchetti con indirizzo appartenente alla rete interna, mettendo in atto un
attacco di tipo IP-spoofing
(falsificazione di indirizzo IP).
D’atra parte il packet filtering non è uno
strumento completo, perché, a causa delle limitate informazioni che è in grado
di analizzare, non può far rispettare alcune regole di accesso che richiedono
informazioni del protocollo applicativo. Inoltre alcuni protocolli non sono
facilmente analizzabili con tecniche di packet filtering: i servizi basati sul
protocollo RPC (Remote
Procedure Call), come ad esempio NFS e NIS (Network Information System), sono difficili da
filtrare perché non sono disponibili su porte logiche prestabilite. A questo
proposito è opportuno osservare che il filtraggio dei servizi è basato
esclusivamente sull’associazione “porta logica” / “servizio”, ma questa
associazione è stabilita solo in maniera convenzionale e può non essere
rispettata. Ad esempio è possibile configurare un server HTTP su una porta
diversa dalla numero 80. Per poter accedere, i client devono specificare il
nuovo numero di porta. [4]
3.2.2
Proxy Service
Un proxy service è un servizio offerto normalmente da un firewall allo scopo di rilanciare le richieste di servizio provenienti da Internet verso la rete interna e viceversa, quando questa è separata da Internet tramite il firewall stesso.
I proxy server vengono usualmente installati su
una delle macchine che realizzano il firewall che prende il nome di application
gateway. Tali server
elaborano richieste per servizi remoti, traducendole in nuove richieste che
risultano provenire dall’application gateway, e le inoltrano in accordo con le
regole di accesso stabilite per i servizi stessi (Figura
6).
In pratica queste macchine danno la possibilità
di mantenere un singolo punto di transito da e verso Internet pur fornendo un collegamento
apparente con tutti gli host della rete, consentendo anche a macchine isolate
da un firewall di usufruire dei servizi di rete.
Se una richiesta di servizio proviene dalla rete
interna, il proxy server presenta al client l’illusione di trattare con il
server reale richiesto, mentre al server presenta l’illusione di trattare con
un client che gira sull’application gateway.
Viceversa, se la richiesta proviene da Internet,
il client comunica col server come se questo girasse sull’application gateway.
A differenza delle tecniche di packet filtering,
che consentono di selezionare il traffico in base alle informazioni dei
protocolli di trasporto e di rete, i proxy server sono normalmente in grado di
prendere decisioni sulle richieste da inoltrare anche in base alle
caratteristiche del protocollo applicativo che trattano. Ad esempio, mentre uno
screenig router può esclusivamente accettare o proibire il traffico FTP, un
proxy FTP può anche selezionare il traffico in base ai comandi specifici del
protocolllo FTP (potrebbe ad esempio essere configurato in maniera tale da
consentire richieste di importazione ma non di esportazione file).
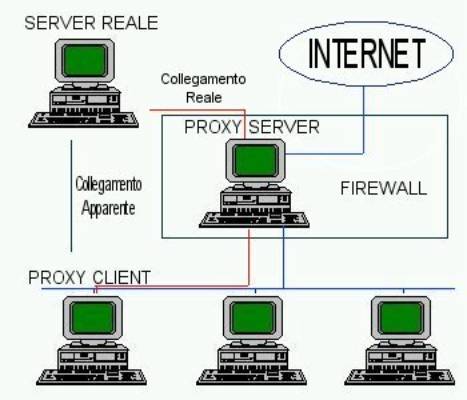
Figura 6: Proxy Service
Anche i proxy service presentano alcuni
svantaggi: non tutti i servizi si basano su protocolli per i quali è possibile
realizzare un proxy server; attualmente sono disponibili solo i proxy server
dei servizi più comuni quali HTTP, FTP, telnet. Inoltre non tutti i protocolli
danno la possibilità di determinare facilmente quali operazioni siano effettivamente
sicure. Ad esempio il protocollo HTTP, pur essendo progettato per funzionare
facilmente con un proxy server, realizza alcune funzioni mediante il
trasferimento di dati che devono essere eseguiti localmente:
per un proxy server non è possibile verificare
la pericolosità di questo tipo di dati in transito. [5]
3.2.3
Logging
Se tutti gli accessi da e verso Internet passano
attraverso un firewall, questo può registrare tali accessi e fornire importanti
statistiche sull’uso della rete. Un firewall dotato di appropriati meccanismi
di allarme, che entrano in funzione quando si verificano attività sospette, può
anche fornire dettagli su eventuali attacchi alla rete.
Gli strumenti che realizzano il filtraggio di
pacchetti (i router) sono normalmente in grado di effettuare il logging dei
pacchetti in transito. Generalmente è opportuno concentrare l’attenzione sul
traffico non consentito, tenere traccia del traffico consentito può comunque
risultare utile in talune circostanze.
I router vengono di solito configurarti in maniera tale da
appoggiarsi al servizio di logging di un host appartenente alla stessa rete
locale. Nei sistemi UNIX il logging è gestito dal demone syslogd. Ogni
messaggio è caratterizzato da un facility code, che informa circa il
sottosistema da cui il messaggio proviene (ad esempio mail system, kernel,
printing system) e da un priorità code, che indica il livello di importanza del
messaggio. Il file di configurazione /etc/syslog.conf controlla come il demone
syslogd gestisce i messaggi in base ai facility e priority code. Un messaggio
può essere ignorato, registrato su uno o più file, mandato al syslogd di un
altro sistema, o mandato a schermo. Inoltre syslogd può essere configurato in
maniera tale da registrare tutti i log in un singolo file o in file distinti in
base ai codici dei messaggi.
Anche i proxy server possono essere utilizzati per generare
dei file di log. Poiché i proxy server sono in grado di analizzare il
protocollo applicativo, riescono ad effettuare il logging in maniera
particolarmente efficace. Un proxy server, oltre a registrare i messaggi
relativi a tutte le richieste di connessione, può registrare anche i comandi
inviati e le risposte ricevute dal server.
Il risultato è un insieme di file di log più utili e più
leggibili rispetto a quello prodotto da uno screening router.
I file di log non sono particolarmente utili se non si
utilizza uno strumento che ne faccia un’analisi automatica in quanto molto
spesso raggiungono dimensioni difficilmente gestibili altrimenti.
3.2.4 Autenticazione
Per una rete privata è spesso indispensabile offrire la
possibilità di utilizzare dall’esterno della rete servizi “autenticati”, quelli
per cui è richiesta l’autenticazione mediante password dell’utente. Questo tipo
di servizi pone gravi problemi di sicurezza; infatti la complessità della
password non costituisce di per sé una garanzia di sicurezza: se la password
viaggia sulla rete, può essere carpita in un qualunque punto di transito. Sono
state progettate varie tecniche di autenticazione: generalmente queste tecniche
hanno in comune la caratteristica che la password eventualmente sottratta non
possa essere riutilizzata in una sessione successiva.
Uno dei sistemi più diffusi è quello conosciuto come
one-time password: una smartcard (carta intelligente) genera, a cadenza
prestabilita o su richiesta dell’utente, una parola che il sistema accetta al
posto della password tradizionale in quanto è in grado di riprodurre la stessa
azione effettuata dalla carta intelligente. In questo modo si accede al sistema
con una parola chiave diversa per ogni collegamento.
Poiché i firewall possono centralizzare e controllare gli
accessi alla rete, sono il punto logicamente più adatto in cui utilizzare
meccanismi di autenticazione per i servizi basati su password.
3.3
Bastion Host
Prima di passare alla descrizione delle architetture di riferimento di un firewall, è utile
descrivere le principali caratteristiche del bastion host, un elemento
normalmente presente in tutte le architetture. Il bastion host è la macchina
deputata ad affacciarsi su Internet ed è pertanto una macchina su cui è
necessario concentrare notevoli sforzi per migliorarne la sicurezza. A seconda
delle architetture, può svolgere una o più funzioni: effettuare il filtraggio
dei pacchetti (screening router), fornire servizi al mondo esterno (information
server), mettere a disposizione proxy service (application gateway ).
I principi utilizzati per realizzare un bastion host sono
un’estensione di quelli che si utilizzano per gestire la sicurezza di un host
qualunque. Uno dei più importanti è quello di rendere semplice la struttura
della macchina: quanti più servizi vengono offerti dal bastion host tanto più
si incorre nel rischio di errori di configurazione e di errori software.
Il bastion host gestisce in genere tutti i servizi che una
rete privata desidera utilizzare o fornire ad Internet e per i quali non si
ritiene sufficiente la protezione mediante packet filtering. In particolare il
bastion host è il punto più indicato per mettere a disposizione tutti quei
servizi che, pur non essendo sicuri, possono essere migliorati con una buona
amministrazione, quali la posta elettronica, FTP,
gopher, HTTP, NNTP (Network News Transfer Protocol), mentre è opportuno
che sul bastion host non siano installate applicazioni non utilizzate. I
servizi considerati sufficientemente sicuri possono invece essere forniti da
altre macchine programmando un opportuno packet filtering. Anche se si è fatto
riferimento ad una singola macchina, in alcune architetture possono essere
presenti più bastion host.
Facendo riferimento ai sistemi UNIX, i servizi che devono
essere necessariamente abilitati su un bastion host sono:
init, swap, page, i tre processi del kernel che gestiscono
tutti gli altri processi;
cron, il processo che serve ad eseguire altri processi ad
un orario fissato o con periodicità definita;
syslogd, il processo che registra messaggi di log dal
kernel e da altri demoni;
inetd, il processo che serve ad avviare alcuni servizi di
rete quando questi vengono richiesti da altre macchine.
Oltre a questi dovranno essere disponibili tutti i server
per i servizi che si è scelto di offrire in base alla politica di sicurezza
della rete, quali ad esempio telnet, FTP, DNS, SMTP.
Poiché il bastion host è per sua stessa natura esposto ad attacchi esterni, è necessario cautelarsi dall’eventualità che un attaccante che sia riuscito a violarlo possa prendere il controllo delle macchine della rete interna. Per questa ragione è importante fare in modo che il bastion host non possa accedere a servizi di rete che prevedono la condivisione di informazioni critiche né che possa offrire alle macchine della rete interna servizi vulnerabili o accedere a servizi vulnerabili sulle macchine interne.
Quello che segue è un elenco dei servizi che è opportuno
disabilitare sul bastion host:
NFS (nfsd, mountd);
NIS (ypserv, ypbind,
ypupdated);
Servizi di booting (tftpd,
bootd, bootpd);
Comandi remoti (rshd, rlogind, rexecd);
Fingerd.
E’ preferibile inoltre che sul bastion host non siano
registrati utenti che non siano l’amministratore di sistema. Infatti la
presenza di utenti generici rende il sistema più vulnerabile sia perché il bastion
host può essere oggetto di attacchi di tipo password guessing (ricerca della
password per tentativi), sia perché gli utenti stessi potrebbero rendere il
sistema più vulnerabile in maniera involontaria. Per questa ragione il bastion
host dovrebbe essere collocato in un luogo fisicamente sicuro e accessibile
tramite console esclusivamente dall’amministratore del sistema. [6]
3.4 Architetture di riferimento
3.4.1
Dual-Homed Host
Un dual-homed host è un calcolatore con almeno due
interfacce di rete, che può agire come un router tra le due reti alle quali
sono collegate le interfacce. La capacità di indirizzare correttamente
pacchetti, nota come IP forwarding, è realizzata dal kernel del sistema operativo.Una
macchina di questo tipo può essere utilizzata come firewall (e in questo caso è
anche il bastion host del firewall) se posta tra una rete privata ed Internet e
se opportunamente configurata come packet filtering e application gateway.
Tuttavia in questo caso la possibilità di instradare pacchetti deve essere
disabilitata, in maniera tale che le due reti su cui si affaccia il dual-homed
host non possano comunicare direttamente (Figura 7).

Figura 7:
Dual-homed host
In un’architettura basata su un dual-homed host i servizi
possono essere forniti solo da questo, mediante proxy server , a meno che non
si scelga di permettere agli utenti la connessione al firewall; si deve però
tenere presente che la presenza di utenti registrati sul firewall rende più
difficile mantenere l’integrità del sistema. L’architettura appena descritta
può essere modificata aggiungendo uno screening router nel punto di connessione
ad Internet. Per quanto l’architettura dual-homed host abbia delle buone
caratteristiche di sicurezza, la scarsa flessibilità produce alcuni svantaggi,
soprattutto nella gestione dei servizi. Infatti gli unici servizi disponibili
sono quelli per cui esiste un proxy server sull’application gateway. [7]
3.4.2 Screened Host
L’architettura screened host viene realizzata mediante più
componenti fisici. L’elemento principale dal punto di vista della protezione
della rete privata è uno screening router , i servizi vengono forniti da un
calcolatore (il bastion host) appartenente alla rete interna che svolge
funzioni di application gateway. In questa architettura il bastion host ha una
sola interfaccia di rete e la separazione della rete interna viene realizzata
dal router , che filtra i pacchetti in maniera tale che solo il bastion host
possa aprire connessioni con la rete esterna. Viceversa, tutti i sistemi
esterni che desiderino collegarsi con la rete privata possono connettersi solo
con il bastion host (Figura 8).
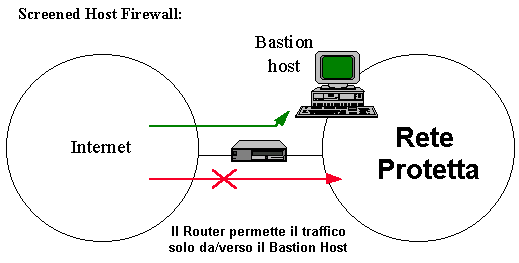
Figura 8: Screened Host
Questa architettura è molto più elastica della precedente e
sono possibili due approcci:
impedire tutti i tipi di connessione da e verso host interni
, eccetto il bastion host, e quindi forzare l’utilizzo dei proxy server sul
bastion host (mediante un opportuno filtraggio da parte del router) (frecce
intere nella Figura 8);
permettere ad altri host interni di aprire connessioni con
Internet per alcuni specifici servizi (frecce tratteggiate nella Figura 8).
Questi due approcci possono essere combinati in modo da
realizzare una politica di sicurezza della rete che si avvicini quanto più
possibile a quella desiderata. [7]
3.4.3 Screened Subnet
In questa architettura il firewall viene realizzato utilizzando
due router che creano una rete, compresa tra loro, detta rete perimetrale, su
cui si trovano le macchine (bastion host) che forniscono i servizi, ad esempio
l’application gateway e il server di posta elettronica (Figura 9).

Figura 9:
Screened Subnet con DMZ
Il router esterno filtra il traffico tra Internet e la rete
perimetrale in accordo con la politica di accesso ai servizi stabilita per la
rete, mentre il router interno protegge la rete privata sia da Internet che
della rete perimetrale consentendo esclusivamente il transito di pacchetti da e
verso i bastion host. E’ possibile configurare i due router in maniera tale da
consentire il transito di traffico che si considera fidato tra Internet e la
rete interna senza la mediazione di application gateway (Figura 9). [7]